Table des matières
Remarques et remerciements
CanFlood est une plateforme expérimentale de modélisation des risques d’inondation open source. Ressources naturelles Canada et IBI Group n’assument aucune responsabilité pour toute erreur ou inexactitude. Les outils fournis dans CanFlood sont uniquement à des fins de commodité, et l’utilisateur est responsable du développement de ses propres tests et de la confiance dans les résultats des modèles.
Pour la dernière version du manuel et du logiciel, veuillez visiter la page du projet : https://github.com/IBIGroupCanWest/CanFlood
Remerciements de développement
Le plugin CanFlood et ce manuel ont été développés par IBI Group sous contrat avec Ressources naturelles Canada (RNCan). Le droit d’auteur est détenu par RNCan et le logiciel est distribué sous la licence MIT.
Termes et conditions d’utilisation
L’utilisation du logiciel décrit dans ce document est régie par certaines conditions générales. L’utilisateur doit reconnaître et accepter d’être lié par les termes et conditions d’utilisation avant que le logiciel puisse être installé ou utilisé.
RNCan accorde à l’utilisateur le droit d’installer CanFlood « le logiciel » et d’utiliser, de copier et/ou de distribuer des copies du logiciel à d’autres utilisateurs, sous réserve des conditions d’utilisation suivantes :
Toutes les copies du logiciel reçues ou reproduites par ou pour l’utilisateur conformément à l’autorité des présentes modalités d’utilisation seront et demeureront la propriété de RNCan.
Les utilisateurs peuvent reproduire et distribuer le logiciel à condition que le destinataire accepte les termes et conditions d’utilisation indiqués dans les présentes.
RNCan est seul responsable du contenu du logiciel. L’utilisateur est seul responsable du contenu, des interactions et des effets de toutes les modifications, le cas échéant, qu’il s’agisse de modules d’extension, d’ensembles de ressources linguistiques, de scripts ou de toute autre modification.
Le nom « CanFlood » ne doit pas être utilisé pour approuver ou promouvoir des produits dérivés du Logiciel. Les produits dérivés du logiciel ne peuvent pas être appelés « CanFlood » et aucune partie du nom « CanFlood » ne doit apparaître dans le nom des produits dérivés.
Aucune partie des présentes conditions générales d’utilisation ne peut être modifiée, supprimée ou effacée du logiciel.
Assentiment
En utilisant ce programme, vous acceptez volontairement ces termes et conditions. Si vous n’acceptez pas ces termes et conditions, désinstallez le programme, supprimez toutes les copies et cessez d’utiliser le programme.
Glossaire
- Probabilités annuelles de dépassement (AEP)
L’inverse de l’ARI.
Intervalles de récurrence annuels (ARI) L’espérance statistique de temps entre les événements dérivée de certaines séries chronologiques observées (par exemple, une inondation d’une magnitude de 100 IRA ou plus s’est produite 10 fois au cours des 1000 dernières années). L’inverse de l’IRA d’un événement est la probabilité de dépassement annuel de cet événement (par exemple, une inondation de 100 IRA a 1 % de chance de se produire chaque année). Souvent, le suffixe “ARI” est remplacé par “-year” (par exemple, une crue de 100 ARI équivaut à une crue de 100 ans). Zone d’intérêt (ZI)
Les étendues spatiales de l’étude ou du modèle
- Système de coordonnées de référence (CRS)
Système utilisé pour localiser et projeter des informations spatiales.
Estimation des dommages annualisés (EAD) Valeur attendue des impacts. Voir Section 5.2.3_. Évaluations des risques d’inondation (FRA)
Un processus formel d’évaluation et de quantification du risque d’inondation
Mesures d’atténuation au niveau de l’objet (ou de la propriété) de l’interface utilisateur graphique (GUI) (PLPM) Interventions agissant à l’échelle micro ou propriété comme les clapets anti-retour ou la mise en sac de sable. Voir Section 5.2.2_. Outil d’évaluation rapide des dommages causés par les inondations (RFDA)
Plugin QGIS développé par IBI Group et la province de l’Alberta pour les calculs de risque d’inondation basés sur des objets (IBI Group et Golder Associates 2015)
- Cadre de modèle d’évaluation dynamique des dommages dus aux inondations basé sur des objets stochastiques (SOFDA)
Modèle de recherche dynamique sur les risques d’inondation inclus dans CanFlood as Risk (L3) (Section5.2.4_)
Niveau de surface de l’eau (WSL) La hauteur d’un peu d’eau au-dessus d’un certain niveau de référence. À ne pas confondre avec la « profondeur d’eau » qui est une hauteur d’eau au-dessus du sol. Service de couverture Web (WCS)
Protocole pour les données spatiales sur Internet
1. Introduction
CanFlood est une boîte à outils de calcul des risques d’inondation transparente et basée sur des objets, conçue pour le Canada. CanFlood facilite les calculs des risques d’inondation avec trois « ensembles d’outils » :
Construire un modèle |buildimage|
Exécuter un modèle |runimage|
Visualiser et analyser les résultats |visualimage|
Chacun d’eux dispose d’un ensemble d’outils pour aider le modélisateur des risques d’inondation dans un large éventail de tâches courantes dans l’élaboration d’évaluations des risques d’inondation au Canada.
Les modèles de risque d’inondation CanFlood sont basés sur des objets, où les conséquences de l’exposition aux inondations sont calculées pour chaque actif (par exemple, une maison) à l’aide d’une fonction de vulnérabilité unidimensionnelle fournie par l’utilisateur (c. et intégrer une gamme d’événements pour obtenir le risque total d’inondation dans une zone. Pour soutenir la diversité des besoins d’évaluation des risques d’inondation et la disponibilité des données à travers le Canada, CanFlood prend en charge trois cadres de modélisation de complexité, d’exigences de données et d’effort croissants (Section 1.1_). Chacun de ces cadres a été conçu pour être flexible et agnostique, permettant aux modélisateurs de mettre en œuvre un outil logiciel et une structure de données uniques tout en maintenant des modèles de risque d’inondation qui reflètent l’hétérogénéité des actifs et des valeurs canadiens. Reconnaissant l’importance de l’infrastructure de protection contre les inondations sur le risque d’inondation dans de nombreuses collectivités canadiennes, les modèles CanFlood peuvent intégrer le potentiel de défaillance dans les calculs de risque. Pour tirer parti de la collection croissante d’ensembles de données de modélisation des risques au Canada, CanFlood aide les utilisateurs à se connecter et à manipuler ces données dans des modèles de risques d’inondation.
Le plugin CanFlood n’est PAS un modèle de risque d’inondation, mais plutôt une plate-forme de modélisation avec une suite d’outils pour aider les utilisateurs à créer, exécuter et analyser leurs propres modèles. CanFlood demande aux utilisateurs de pré-collecter et d’assembler les ensembles de données décrivant les risques d’inondation dans leur zone d’étude (voir Section 0_). Une fois l’analyse dans CanFlood terminée, les utilisateurs doivent appliquer leur propre jugement et leur expérience pour associer le contexte et les conseils nécessaires à tout rapport avant de communiquer les résultats aux décideurs. Les résultats de CanFlood ne doivent pas être utilisés pour prendre des décisions, mais plutôt pour informer les décisions ainsi que toutes les autres dimensions et critères pertinents pour la communauté à risque.
1.1 Contexte
La dévastation des inondations du sud de l’Alberta et de Toronto en 2013 a déclenché une transition au Canada de l’approche traditionnelle basée sur les normes, où la protection contre les inondations est conçue pour un seul niveau de sécurité, vers une approche basée sur les risques. Cette nouvelle approche basée sur les risques reconnaît qu’une planification solide doit tenir compte de la vulnérabilité et de l’ensemble des inondations susceptibles de nuire à une communauté plutôt que de se concentrer sur un événement de conception unique et arbitraire. De plus, une vue basée sur les risques permet aux décideurs d’optimiser quantitativement les mesures d’atténuation pour leur communauté, aidant les juridictions aux budgets réduits à étendre davantage les protections. Le fondement des décisions prises dans le cadre d’une gestion des inondations basée sur les risques est une évaluation des risques, qui est :
Une méthodologie pour déterminer le risque en analysant les dangers potentiels et en évaluant les conditions de vulnérabilité existantes qui, ensemble, pourraient potentiellement nuire aux personnes exposées, aux biens, aux services, aux moyens de subsistance et à l’environnement dont ils dépendent (UNISDR 2009).
Pour quantifier les risques, les évaluations modernes des risques intègrent des données sur l’environnement naturel et bâti à des modèles prédictifs. Appliquée à la gestion des risques d’inondation, une analyse de risque est très sensible aux composantes spatiales du risque : vulnérabilité (qu’est-ce qui a été construit où et à quel point les eaux de crue sont-elles nocives ?) et aléa (où et quelle peut être l’intensité des inondations ?). L’évaluation de ces composants est généralement accomplie avec une chaîne d’activités telles que la collecte, le traitement, la modélisation et le post-traitement des données pour arriver aux mesures de risque souhaitées. Les principaux composants d’une évaluation typique des risques d’inondation sont l’évaluation des risques pour synthétiser les ensembles de données spatiales sur la probabilité d’exposition et une évaluation des dommages pour estimer les dommages aux biens à partir des résultats de l’évaluation des risques, suivie de la quantification des risques qui utilise les probabilités d’événement pour estimer les dommages moyens.
1.1.1 Motivation
Compte tenu de la limitation des outils existants et du besoin croissant de minimiser les dommages causés par les inondations au Canada grâce à une meilleure compréhension des risques d’inondation, RNCan a cherché à développer et à maintenir un outil open source flexible adapté au Canada. Un tel outil standardisé :
réduire le coût des évaluations individuelles des risques d’inondation (FRA) en consolidant les coûts de développement et de maintenance des logiciels ;
accroître la transparence et la normalisation des FRA pour améliorer les comparaisons de risque et de mise à jour entre les zones d’étude ;
encourager les communautés à effectuer des FRA supplémentaires en réduisant l’opacité et les coûts et en augmentant la sensibilisation ;
faciliter et motiver la normalisation et la collecte d’ensembles de données sur les risques d’inondation ; et
faciliter une modélisation plus sophistiquée et rationalisée.
1.1.2 Lignes directrices
Série de lignes directrices fédérales sur la cartographie des inondations
« La série de lignes directrices fédérales sur la cartographie des inondations a été élaborée sous la direction du Comité de cartographie des inondations, un partenariat entre Sécurité publique Canada, Ressources naturelles Canada, Environnement et Changement climatique Canada, Conseil national de recherches du Canada, Recherche et développement pour la défense Canada, Forces armées canadiennes , Infrastructure Canada et Relations Couronne-Autochtones et Affaires du Nord Canada. Il s’agit « d’une série de lignes directrices permanentes qui aideront à faire progresser les activités de cartographie des inondations à travers le Canada » (Sécurité publique Canada 2018). Les documents publiés peuvent être trouvés en recherchant sur le Web « Federal Flood Mapping Guidelines Series ». <https://www.publicsafety.gc.ca/cnt/mrgnc-mngmnt/dsstr-prvntn-mtgtn/ndmp/fldpln-mppng-en.aspx>`__ Les éléments suivants sont particulièrement pertinents pour CanFlood :
Lignes directrices fédérales sur l’estimation des dommages causés par les inondations pour les bâtiments et les infrastructures (en cours d’élaboration)
Procédures fédérales d’évaluation des risques d’inondation (en cours d’élaboration)
Directives internationales
+————————+————+———-+ ———-+———-+———-+———-+—— —-+ |Juridiction/Autorité | Ligne directrice (référence) | +========================+============+===========+ ==========+==========+==========+==========+====== ====+ | Royaume-Uni | Gestion des risques d’inondation et d’érosion côtière – Manuel | | | (Penning-Rowsell et al. 2013) | +————————+————+———-+ ———-+———-+———-+———-+—— —-+ | États-Unis | Méthodologie d’estimation des pertes multirisques, modèle d’inondation : | | | | | | Manuel technique Hazus-MH MR2 (FEMA 2012) | | | Analyse basée sur les risques pour les études de réduction des dommages causés par les inondations (USACE 1996) | | | | | | Lier l’assurance contre les inondations au risque d’inondation pour les structures de faible altitude | | | plaine inondable (Conseil national de recherches 2015) | | | Principes d’analyse des risques pour les ressources en eau (IWR et USACE 2017) | +————————+————+———– ———-+———-+———-+———-+—— —-+
1.1.3 Modèles basés sur les risques et les événements
Historiquement, la gestion des crues a impliqué des décisions basées sur un seul « événement de conception » hypothétique, souvent arbitraire (par exemple, un débit sur 100 ans). Cette approche a laissé de nombreuses communautés sous-défendues et contribue probablement à l’augmentation des pertes dues aux inondations récemment observées au Canada (Frechette 2016). En réponse à cela, la gestion moderne des inondations reconnaît la nécessité d’évaluations complètes basées sur les risques qui évaluent une gamme d’événements et leur probabilité et leurs conséquences dans la planification de la gestion. CanFlood a été conçu pour soutenir la gestion moderne basée sur les risques en intégrant une gamme d’événements d’inondation (par exemple, des événements de 10 ans, 50 ans, 100 ans, 200 ans) et leurs probabilités dans des modèles basés sur les risques qui calculent les paramètres de risque . Cependant, étant donné que CanFlood calcule les impacts basés sur les événements avant tout calcul de risque,
1.2 Utilisateurs visés
Le plug-in CanFlood est destiné aux utilisateurs disposant de données spatiales et de vulnérabilité souhaitant effectuer une évaluation des risques d’inondation (FRA) basée sur des objets au Canada. CanFlood est destiné aux praticiens du risque d’inondation ayant l’expertise suivante :
Analyse des risques d’inondation basée sur les objets
QGIS (novice)
Voir la section 1.1.2_ pour un résumé des lignes directrices et des procédures relatives aux FRA au Canada.
1.3 Niveaux du modèle de risque
Les objectifs et les applications de l’analyse des risques d’inondation sont aussi divers que les communautés qu’ils desservent. Pour s’adapter à cette large gamme, CanFlood contient trois types de modèles de risque avec une complexité croissante, comme résumé dans le Tableau 1-1_ et discuté dans la Section 5.2_. Pour soutenir la construction et l’analyse de ces modèles de risque, CanFlood inclut également les ensembles d’outils « Construire » et « Résultats » respectivement (Section 5.1_ et Section 5.3_). La connexion de tous ces éléments pour effectuer une analyse est abordée dans la Section 4.5_ et des didacticiels similaires sont fournis dans la Section 6.
Tableau 1-1 - Résumés au niveau du modèle CanFlood
FRA rapide. expertises de type bureautique : premières approximations pour identifier les domaines où un travail plus détaillé est nécessaire
Des évaluations plus détaillées lorsqu’une évaluation plus approfondie du potentiel de perte est justifiée
Etude détaillée des pertes potentielles et quantification robuste des incertitudes
Flux de travail
Section 3.1_
Appendice B
Noms des outils de modèle CanFlood
Risque (L1)
Impacts (L2) et Risque (L2)
Risque (L3) (alias SOFDA)
Données requises
meugler
moyen
haute
Niveau d’effort de modélisation (par actif)
meugler
meugler
haute
Complexité du modèle
meugler
moyen
haute
Fonctions d’impact
aucun (inondation uniquement)
par objet
par objet, non compilé
Quantification de l’incertitude
rien
rien
modélisation stochastique
PLPM
Oui
Oui
Oui
Dynamique du risque
non
non
Oui
Géométrie de l’actif
point, polygone, ligne
point, polygone, ligne
point
Contributions
inventaire des actifs, événements dangereux, DTM (facultatif), événements de défaillance associés (facultatif)
identique à L1 plus : Ensemble de fonctions d’impact
inventaire des actifs, tables WSL, fonctions de vulnérabilité (non compilées), paramètres dynamiques, autres
Sorties primaires
impacts totaux (“r_ttl”), impacts par actif (“r_passet”), tracé de la courbe de risque
idem L1
tableau des expositions, graphiques récapitulatifs des impacts annualisés (résumé et par actif), autres
Adapté de Penning-Rowsell et al. (2019)
1.4 Fichiers de contrôle
Les modèles CanFlood sont conçus pour écrire et lire à partir de petits « fichiers de contrôle ». Ceux-ci facilitent la création et le partage d’un modèle ou d’un scénario spécifique, et de conserver une trace de la manière dont l’ensemble de résultats a été généré. Celles-ci facilitent également l’apport d’une petite modification à un fichier d’entrée commun (par exemple, l’inventaire des actifs) et la réplication de cette modification dans toutes les exécutions de scénario. Les fichiers de contrôle ne contiennent aucune donnée (volumineuse), uniquement des valeurs de paramètres et des pointeurs vers les ensembles de données requis par un modèle CanFlood. Un stockage de fichiers et des conventions de dénomination diligents et cohérents sont essentiels pour une expérience de modélisation agréable. La plupart des paramètres du fichier de contrôle et des fichiers de données peuvent être configurés dans l’ensemble d’outils « Build » ; cependant, certains paramètres avancés doivent être configurés manuellement (voir Section5.2_ pour une description complète des paramètres du fichier de contrôle) 1 . La collection d’entrées de modèle et de fichier de contrôle configuré est appelée un « package de modèle », comme illustré à la Figure 1-1_ . Plus d’informations sur les fichiers d’entrée sont fournies dans la Section0_ .
Figure 1-1. Plus d’informations sur les fichiers d’entrée sont fournies dans la Section0_ .
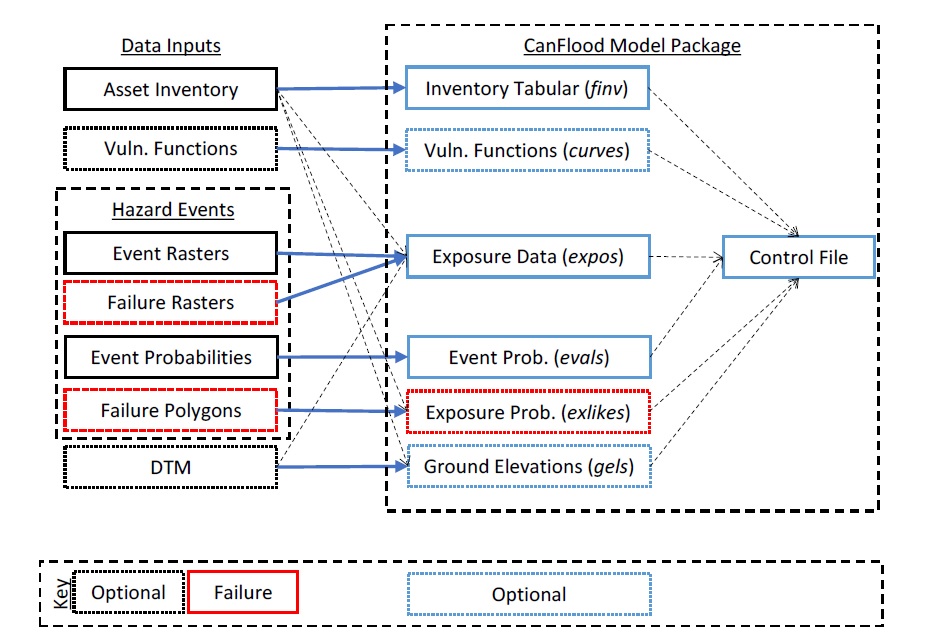
Figure 1-1 : Ensemble de modèles CanFlood L2 et diagramme de relation entre les données et les entrées.
2. Installation
Toutes les instructions d’installation sont disponibles sur GitHub : https://github.com/RNCan/CanFlood
Une fois installé, vous devriez voir les trois boutons CanFlood sur votre barre d’outils QGIS :

Des outils supplémentaires sont fournis dans le menu des plugins de QGIS.
3. Applications et flux de travail
Le plugin CanFlood contient une collection d’outils conçus pour prendre en charge les modélisateurs de risques d’inondation avec une gamme de tâches courantes. Pour ce faire, CanFlood est flexible : il permet aux utilisateurs de relier entre eux les outils et les séquences nécessaires pour accomplir la tâche à accomplir. La réalisation d’une évaluation des risques d’inondation à l’aide de CanFlood nécessite une expertise en modélisation des risques d’inondation, certaines procédures comme celles référencées dans la Section 1.1.2_ , et utilise généralement les étapes suivantes :
Identifier les objectifs, la portée et le but de l’évaluation.
Sélection du niveau de modèle CanFlood approprié (Section 1.3_) puis identification des données d’entrée nécessaires.
Collecter et préparer les données d’entrée nécessaires (Section0_).
Construire le package du modèle CanFlood (voir ci-dessous).
Exécuter le package de modèle CanFlood à l’aide de l’outil de modèle approprié (Section5.2_).
Utilisation des outils de « résultats » de CanFlood pour préparer des diagrammes et des cartes (section 5.3_).
Évaluer, documenter et communiquer les résultats, le contexte et l’incertitude.
Comme indiqué dans les références de la section, bon nombre de ces étapes doivent être effectuées en dehors de la plate-forme CanFlood.
Modèles de construction
La plupart des flux de travail dans CanFlood nécessitent que l’utilisateur emploie une séquence similaire d’outils « Construire » décrits dans la section 5.1_ pour préparer le package de modèle CanFlood (Figure 1-1_) à partir des données d’entrée. La figure 3-1_ montre un flux de travail typique de « Configuration » à « Validation ». L’inclusion ou non des étapes facultatives indiquées sur le schéma dépendra des éléments suivants :
Niveau du modèle de risque : les modèles L2 nécessitent des fonctions de vulnérabilité (“courbes”) (voir Section3.2_).
Défaillance de la défense : les modèles L1 ou L2 incorporant des défaillances de protection nécessitent des événements de défaillance associés (rasters de défaillance et polygones de défaillance) (voir Section 3.3_).
Hauteurs d’actifs : Les modèles L1 ou L2 incorporant des inventaires d’actifs avec des données de hauteur d’objet par rapport au sol nécessitent des données d’élévation du sol (“gels”).
Type d’exposition : les modèles L1 ou L2 avec des ressources géométriques non ponctuelles évaluant l’exposition en pourcentage d’inondation (Section5.1.3_) nécessitent une couche DTM.
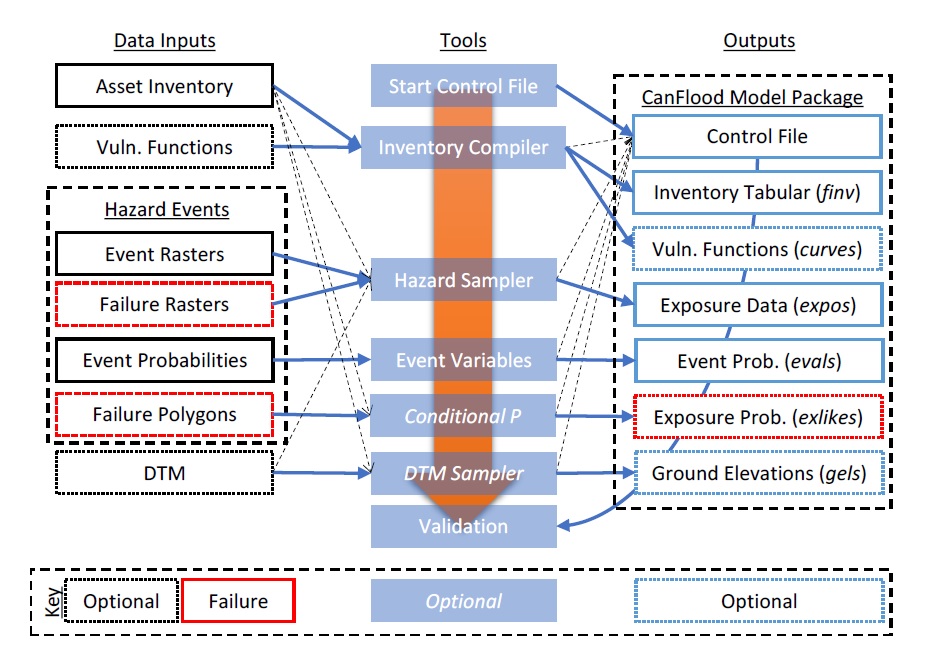
Figure 3-1 : Flux de travail de construction de modèle typique à l’aide des outils « Construire » de CanFlood de « Configuration » à « Validation ». Les entrées de données sont décrites dans la Section 0 tandis que les outils et les sorties sont décrits dans Section5.1_
Plus d’informations et d’outils supplémentaires pour prendre en charge la construction de modèles sont fournis dans la Section5.1_ .
Le reste de cette section résume certains types d’analyse ou flux de travail typiques utilisant les modèles de risque résumés dans la section 1.3_ et discutés en détail dans la section 5.2_ . Tous ces workflows sont basés sur les risques, en ce sens qu’ils intègrent un large éventail de probabilités d’événements et calculent des mesures de risque. Les didacticiels de la section 6 fournissent des instructions étape par étape et les données d’entrée d’accompagnement pour illustrer ces flux de travail.
3.1. Évaluation du risque (L1) basée sur l’exposition
Les évaluations basées sur l’exposition (L1) quantifient la probabilité d’exposition binaire des actifs aux inondations (humide contre sec). Cela peut être utile pour les évaluations initiales, lorsque les ressources et les données sont limitées, afin d’identifier les domaines nécessitant une étude plus approfondie. Dans CanFlood, cela est accompli en collectant des données, en créant un modèle de risque (L1), en exécutant le modèle et en évaluant les résultats. Contrairement aux évaluations basées sur la vulnérabilité (L2, Section3.2_), les évaluations basées sur l’exposition (L1) ne capturent pas l’influence de la profondeur de l’inondation sur le risque. En d’autres termes, une maison avec une mare dans la cour serait comptée de la même manière qu’une maison entièrement sous l’eau. Cependant, les évaluations basées sur l’exposition (L1) peuvent être utilisées pour estimer des paramètres de risque supplémentaires en appliquant les paramètres d’échelle de CanFlood (par exemple, estimer les pertes de récolte en multipliant la zone inondée par une constante de perte/zone). Les évaluations basées sur l’exposition (N1) peuvent incorporer une évaluation de la défaillance de la défense si des données sur la probabilité d’exposition sont disponibles (Section 3.3_). La Figure 3-1_ et la Figure 3-2_ résument un workflow de risque (L1) typique. Pour plus d’informations sur le modèle Risque (L1), voir Section 5.2.1_.
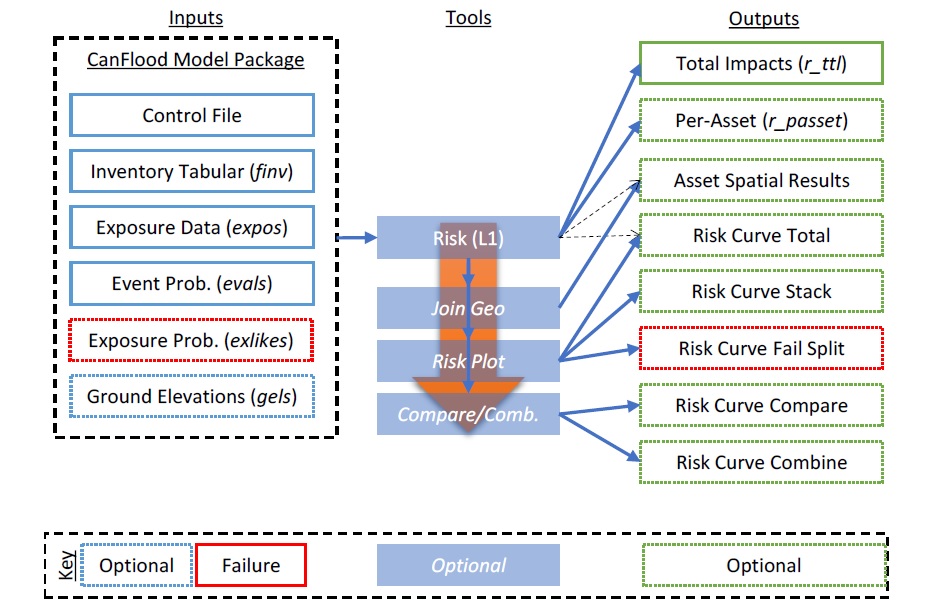
Figure 3-2 : Flux de travail de risque typique (L1) (construction post-modèle).
3.2. Évaluation du risque (N2) basée sur la vulnérabilité
Les évaluations basées sur la vulnérabilité (L2) quantifient le risque de certains impacts d’inondation sur les actifs où l’impact peut être lié à la profondeur. Les modèles de risque qui considèrent la vulnérabilité en fonction de la profondeur de l’inondation sont couramment utilisés pour évaluer le risque d’inondation des bâtiments, du contenu des bâtiments et des infrastructures. Dans CanFlood, une telle évaluation est réalisée en collectant des données, en construisant ou en collectant des fonctions de vulnérabilité, en construisant un modèle de risque (L2), en exécutant ledit modèle, puis en évaluant les résultats. L’élément le plus difficile de ce processus est souvent la collecte ou la construction de fonctions de vulnérabilité (Section 4.3_) pour lesquelles les futures versions de CanFlood peuvent fournir une assistance. Les évaluations basées sur la vulnérabilité (L2) intègrent généralement une évaluation de l’échec de la défense (Section 3.3_). La Figure 3-1_ et la Figure 3-3_ résument un workflow de risque (L2) typique.
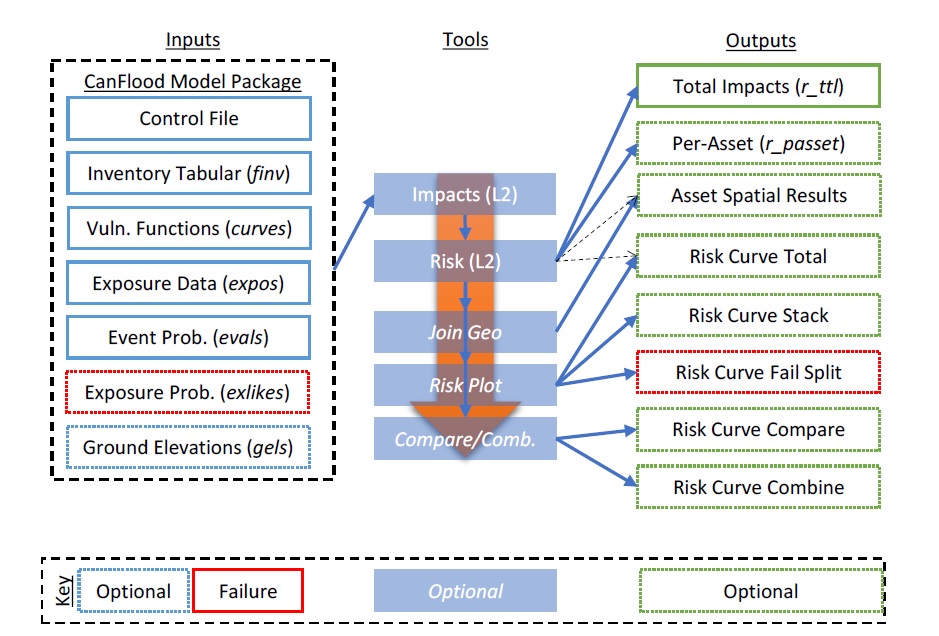
Figure 3-3 : Workflow de risque typique (L2) (construction post-modèle).
3.3. Échec de la défense
De nombreuses zones développées au Canada dépendent d’une certaine forme d’infrastructure de protection contre les inondations (par exemple, des digues ou des pompes de drainage) pour réduire l’exposition des actifs. Toute infrastructure de ce type peut tomber en panne lors d’une inondation. Ignorer ce potentiel de défaillance (P fail =0) sous-estimera le risque réel d’inondation dans une zone (biais négatif du modèle). Supposer qu’une telle infrastructure échouera toujours (P fail =1) peut considérablement surestimer le risque d’inondation (biais positif du modèle). L’une ou l’autre hypothèse réduira la confiance dans le modèle et la qualité de toutes les décisions de gestion des crues prises à partir de celui-ci. Dans de nombreuses régions du Canada, la protection contre les inondations joue un rôle si important dans la mécanique de l’exposition qu’un traitement binaire de la probabilité de défaillance (P fail = 0 ou 1) rendrait la métrique de risque calculée du modèle inutile.
Une application courante de cette capacité est l’incorporation de la fragilité des digues dans un modèle de risque. Souvent, ces zones d’étude auront des groupes d’actifs protégés par des digues, où chaque actif est vulnérable à un point de rupture n’importe où le long d’un anneau de digue. Cette situation peut être analysée en discrétisant la digue en segments, en estimant la zone d’influence d’une brèche le long de chaque segment (pour l’événement j), en estimant la probabilité conditionnelle que cette brèche se produise (pendant l’événement j) et en développant des rasters de danger. pour les conditions de rupture. Des professionnels hydrotechniques et géotechniques qualifiés doivent être engagés pour effectuer cette analyse et générer les intrants requis par CanFlood, comme résumé dans la section 4.2_.
3.3.1. Flux de travail
L’échec de la défense est intégré aux calculs de risque pendant les flux de travail Risque (L1) et Risque (L2) de CanFlood avec les étapes générales suivantes :
Collecter l’ensemble de rasters d’événements dangereux (Section 4.2_) et les informations sur le profil de digue, la fragilité et la zone d’influence (Section 4.5_).
Calculez la probabilité de rupture de la digue de chaque événement dangereux et mappez-la sur la zone d’influence de la digue à l’aide de l’outil « Dike Fragility Mapper » (Section5.4.1_) pour obtenir l’ensemble « polygone de défaillance ».
À partir des « polygones de défaillance », extrayez, résolvez et attribuez des probabilités de défaillance conditionnelles pour chaque événement de défaillance dans l’ensemble de données sur les probabilités d’exposition résolues (« exlikes ») à l’aide de l’outil « P conditionnel » (Section5.1.5_).
Exécutez le modèle de risque (L1) ou de risque (L2) pour utiliser les algorithmes de CanFlood pour calculer les valeurs attendues en cas d’échec de la défense (Section5.2.3_ Événements avec échec).
La figure 3-4_ résume l’algorithme complet de la valeur attendue de CanFlood.
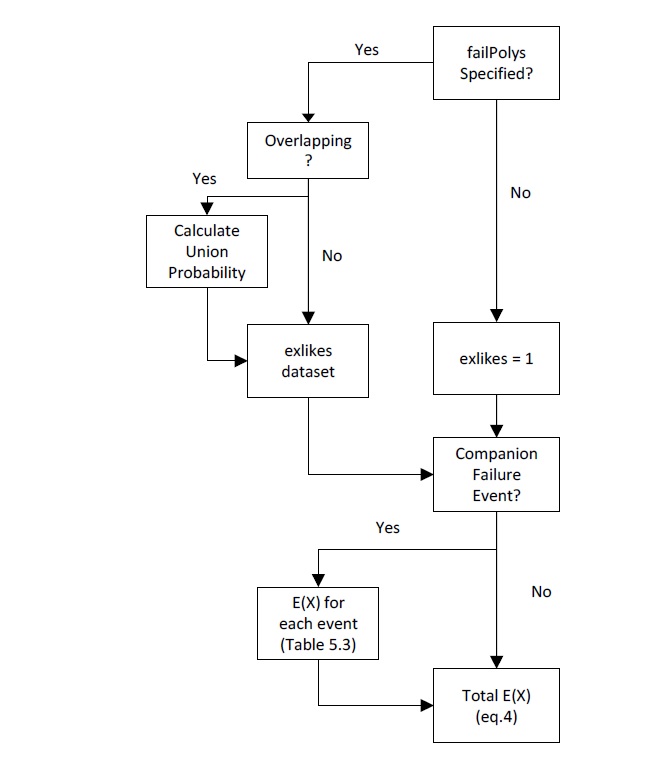
Figure 3-4 : Algorithme de calcul de la valeur attendue (E(X)) de l’outil de risque (L1 et L2) de CanFlood
3.3.2. Relations événementielles
Pour calculer les valeurs attendues (dans des modèles plus complexes), l’application à la fois de l’outil « P conditionnel » et des modèles de risque nécessite de prendre en compte la relation entre les événements fournis par l’utilisateur. En d’autres termes, lorsque plusieurs échecs sont spécifiés, il faut spécifier comment ces échecs doivent/ne doivent pas être combinés. Le calcul et l’intégration des corrélations de défaillance entre les éléments d’un système de défense nécessitent une compréhension sophistiquée et mécaniste du système qui dépasse la portée de CanFlood. À titre d’approximation alternative, CanFlood inclut deux hypothèses de base, résumées à la figure 3-5_, pour la relation entre les éléments de défaillance. Ces hypothèses alternatives sont fournies pour permettre à l’utilisateur de tester la sensibilité du modèle aux corrélations des éléments de défaillance ;
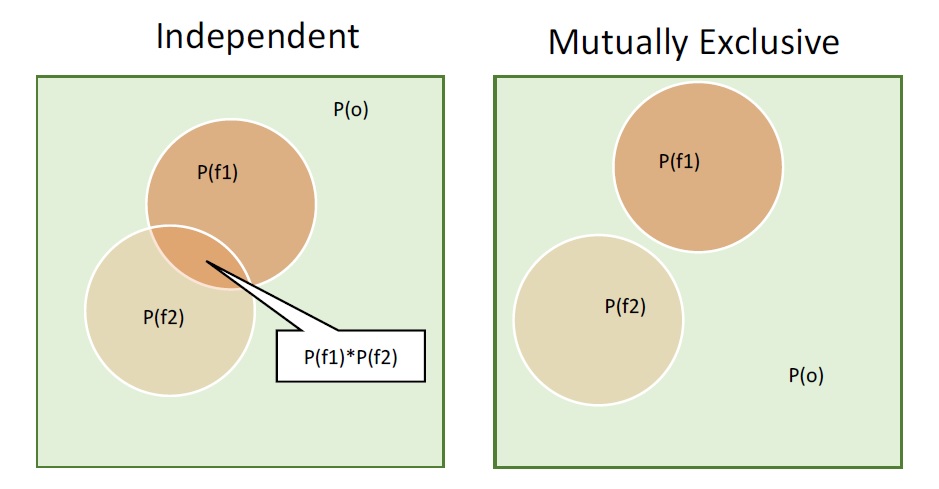
Figure 3-5 : Exemple de diagramme d’espace de probabilité montrant deux événements soit [à gauche] indépendants, soit [à droite] mutuellement exclusifs, où « P(o) » est la probabilité d’absence de défaillance.
4. Données d’entrée et données requises
Les modèles CanFlood sont aussi utiles que les ensembles de données avec lesquels ils sont construits. Vous trouverez ci-dessous un résumé des principaux ensembles de données que l’utilisateur doit collecter et compiler avant de créer un modèle CanFlood.
4.1. Inventaire des actifs
L’inventaire des actifs (“finv”) est une liste complète des objets ou actifs dont l’exposition sera évaluée par les routines du modèle CanFlood. L’inventaire des actifs est un ensemble de données spatiales qui nécessite les champs suivants lorsqu’il est utilisé dans les modèles de risque (L1) :
fX_scale : valeur de mise à l’échelle de la fonction de vulnérabilité (par exemple, surface au sol) ;
fX_elv : élévation pour ancrer la fonction de vulnérabilité (par exemple, hauteur du premier étage + MNT) ;
géométrie : données géospatiales utilisées pour localiser l’actif pour l’échantillonnage ;
FieldName Index (cid) : entier identifiant l’actif unique utilisé pour lier les ensembles de données.
Pour les modèles Impacts (L2) et Risque (L2), les champs supplémentaires suivants sont requis :
fX_tag : valeur indiquant au modèle quelle fonction de vulnérabilité affecter à cet actif ;
fX_cap : valeur de plafonnement de la prédiction de vulnérabilité (par exemple, valeur d’amélioration).
Des champs supplémentaires sont autorisés mais ignorés par CanFlood. L’espace réservé « X » illustré ci-dessus est appelé « nestID » et est utilisé pour regrouper les quatre attributs clés qui paramétrent une « fonction imbriquée » requise par le modèle Impacts (L2) (Section5.2.2). L’ensemble d’outils « Créer » fournit un outil « Constructeur d’inventaire » qui peut remplir un modèle d’inventaire pour plus de commodité ; Cependant, remplir ce modèle pour une zone d’étude nécessite généralement une analyse approfondie des données en dehors du plug-in CanFlood.
4.2. Événements dangereux
CanFlood requiert un ensemble d”« événements dangereux » pour calculer l’exposition et le risque d’inondation. Pour un calcul de risque, chaque événement doit avoir :
Probabilité de l’événement : probabilité que l’événement se produise. Cela peut être entré sous forme de probabilités de dépassement annuel (AEP) ou d’intervalles de récurrence annuels (ARI). Souvent, ceux-ci sont élaborés à l’aide d’une analyse statistique des crues passées. Comme ces informations ne sont pas contenues dans le fichier de données raster lui-même, la meilleure pratique consiste à les inclure dans le nom de la couche.
Raster d’événement : emplacement et WSL de l’événement d’inondation. L’outil « Hazard Sampler » de CanFlood (Section5.1.3_) s’attend à ce qu’il s’agisse d’un fichier de données raster, mais les routines de modèle de CanFlood ne nécessitent que les données d’exposition tabulaires (« expos »). Les valeurs doivent être relatives à la référence du projet (WSL) et sont généralement développées à l’aide d’un logiciel de modélisation hydraulique.
Événements de défaillance associés (facultatif) : contient des informations sur la probabilité et l’exposition résultante d’une défaillance du système de protection contre les inondations pendant l’événement dangereux. Chaque événement dangereux peut se voir attribuer plusieurs événements de défaillance (voir la section 1.4_) en spécifiant la même probabilité d’événement pour chacun dans l’ensemble de données « evals » (voir la section 5.1.4_).
o Raster d’échec : emplacement et WSL de l’événement d’échec associé.
o Polygone de défaillance : couche de polygone de probabilité d’exposition conditionnelle avec des caractéristiques indiquant l’étendue et la probabilité de défaillances d’éléments pendant l’événement. L’outil « Dike Fragility Mapper » (Section5.1.5_) fournit un ensemble d’algorithmes pour préparer ces polygones à partir d’informations sur la fragilité des digues et de rasters d’événements typiques. Ces polygones de défaillance sont nécessaires à l’outil « Conditionnel P » pour générer l’ensemble de données sur les probabilités d’exposition résolues (« exlikes ») requis par les modules Risque (L1) et Risque (L2).
4.3. Ensemble de fonctions de vulnérabilité
Pour le modèle Impacts (L2), CanFlood requiert une bibliothèque de fonctions d’impact avec une fonction pour chaque étiquette d’actif dans l’inventaire. Le fichier de données est une feuille de calcul .xls, où chaque onglet correspond à une fonction d’impact distincte. Chaque onglet contient :
métadonnées sur la fonction (non utilisées par CanFlood); et
une fonction 1D traduisant l’exposition à l’impact.
Un exemple est fourni ci-dessous avec une description. Au cours du modèle Impacts (L2), chaque actif interpole sa fonction de vulnérabilité à la valeur d’exposition (à partir de l’ensemble de données « expos ») pour estimer la valeur d’impact. En règle générale, les variables d’exposition sont la profondeur et les variables d’impact sont les dommages, mais l’utilisateur peut personnaliser le modèle en remplissant l’ensemble de données « expos » avec des variables d’exposition alternatives et en développant des fonctions de vulnérabilité avec des sorties alternatives (par exemple, personnes déplacées = f(pourcentage inondé) ).
Tableau 4-1 : Exigences et description du format de la fonction d’impact CanFlood.
+————————+———————— —+———————–+———————- –+ | Champ | Exemple de valeur | Descriptif | Obligatoire | +========================+======================== ===+=======================+====================== ==+ | balise | 02Office.inEq.comp | Variable de liaison utilisée | VRAI | | | | attribuer ceci | | | | | fonction à un atout | | | | | dans l’inventaire | | +————————+———————— —+———————–+———————- –+ | desc | une description | Description détaillée | FAUX | | | | de l’impact | | | | | fonction. | | +————————+———————— —+———————–+———————- –+ | source | Sondage BCStats PNR (2020) | Source de données principale | FAUX | | | | pour l’impact | | | | | fonction. | | +————————+———————— —+———————–+———————- –+ | emplacement | C.-B. LowerMainland | Situation géographique | FAUX | | | | d’applicable | | | | | actifs | | +————————+———————— —+———————–+———————- –+ | date | 2020 | Période d’application | FAUX | +————————+———————— —+———————–+———————- –+ | impact_units | $CAD | Unités d’impact | FAUX | | | | sortie (après mise à l’échelle) | | +————————+———————— —+———————–+———————- –+ | exposition _unités | m | Unités de prévu | FAUX | | | | entrée d’impact | | +————————+———————— —+———————–+———————- –+ | scale_units | m2 | Unités de prévu | FAUX | | | | entrée d’échelle | | +————————+———————— —+———————–+———————- –+ | exposition_var | hauteur d’eau de | Variable d’attendu | FAUX | | | rez-de-chaussée | entrée d’exposition | | +————————+———————— —+———————–+———————- –+ | impact_var | réparation de bâtiments et | Variable d’impact | FAUX | | | coût de restauration | sortie (après | | | | estimation | mise à l’échelle) | | +————————+———————— —+———————–+———————- –+ | échelle_var | surface au rez-de-chaussée | Description de | FAUX | | | | échelle attendue | | | | | variable | | +————————+———————— —+———————–+———————- –+ | exposition | impact | En-tête pour l’exposition- | VRAI | | | | fonction d’impact | | +————————+———————— —+———————–+———————- –+ | 0 | 0 | Première exposition-impact | VRAI | | | | entrée | | +————————+———————— —+———————–+———————- –+ | 0,305 | 394,56 | … | VRAI | +————————+———————— —+———————–+———————- –+ | 0,914 | 543.05 | Dernière exposition-impact | VRAI | | | | entrée | | +————————+———————— —+———————–+———————- –+
4.4. Modèle numérique de terrain (MNT)
Un DTM de projet n’est requis que pour les modèles avec des hauteurs d’actifs relatives (ELV).
4.5. Informations sur la digue
Pour utiliser le module « Dike Fragility Mapper » (Section5.4.1_) afin de générer l’ensemble de « polygones de défaillance », les informations suivantes sur le système de digues de la zone d’étude sont nécessaires :
Alignement des digues : cette couche de lignes contient les informations suivantes sur les digues d’étude :
o face de la digue : indiquée par la direction de l’élément, cela indique à CanFlood de quel côté de l’élément doit échantillonner le WSL
o la position horizontale de la crête de la digue (c’est-à-dire la position des éléments)
o comment chaque digue doit être segmentée dans l’analyse (où chaque caractéristique représente un segment)
o l’identifiant de la digue (pour combiner plusieurs segments sur une même parcelle)
o tous les tampons de franc-bord qui devraient être appliqués (par exemple, pour simuler l’ensachage)
o quelle courbe de fragilité doit être utilisée pour calculer la probabilité de défaillance de ce segment.
Bibliothèque de fonctions de fragilité des digues : ce type spécial de fonction d’impact (Section 4.3_) relie le WSL par rapport à l’élévation de la crête du segment (c’est-à-dire le franc-bord) à la probabilité de défaillance de ce segment (et de réalisation du WSL de défaillance fourni) . Le développement de ces relations nécessite souvent des données sur les propriétés mécaniques (par exemple, fondation, noyau) et de réparation d’urgence (par exemple, l’accessibilité aux véhicules d’entretien) et une analyse et une expertise géotechniques sophistiquées. Alors que les performances de la digue sont généralement sensibles à plus de types de chargement que le franc-bord, CanFlood ne prend en charge que les calculs de fragilité à variable unique.
Zones d’influence des segments de digues : ces polygones fournissent la géométrie de la zone où les actifs seraient touchés par la défaillance d’un segment. En général, cela est similaire à l’étendue du raster de défaillance (par exemple, les résultats d’un essai de brèche dans un modèle hydraulique).
Modèle numérique de terrain (MNT) de la crête de la digue : il s’agit généralement du même ensemble de données que celui décrit à la section 4.4 ; cependant, l’évaluation des digues est particulièrement sensible aux petits changements d’élévation et les MNT comportent souvent des erreurs ou des artefacts autour des crêtes des digues s’ils ne sont pas construits pour la modélisation des crues. Par conséquent, les utilisateurs doivent mettre l’accent sur la qualité DTM autour des crêtes des digues lors de l’exécution d’une analyse de fragilité.
5. Ensembles d’outils
Cette section décrit en détail l’utilisation et la fonction des ensembles d’outils de CanFlood.
5.1. Construire
L’ensemble d’outils de construction contient une suite d’outils résumés dans le Tableau 5-1_ destinés à aider le modélisateur des risques d’inondation dans la construction des modèles CanFlood L1 et L2.
Tableau 5-1 : Résumé des outils de création
+————————+———————— —+———————–+—————-+—– ——————–+ | Nom de l’onglet | Nom de l’outil | Descriptif | Entrées | Sorties | +========================+======================== ===+=======================+================+===== ====================+ | Configuration | Démarrer le fichier de contrôle | crée un contrôle | nom et | Fichier de contrôle | | | | Modèle de fichier | précision | Modèle | +————————+———————— —+———————–+—————-+—– ——————–+ | Inventaire | Constructeur d’inventaire | Construit un finv | couche vectorielle, | vecteur d’inventaire | | | | modèle | attributs | couche (“finv”) | +————————+———————— —+———————–+—————-+—– ——————–+ | Inventaire | Vuln. Bibliothèque de fonctions | GUI pour sélectionner un | | Vulnérabilité | | | | Ensemble de fonctions | | Ensemble de fonctions | +————————+———————— —+———————–+—————-+—– ——————–+ | Inventaire | Compilateur d’inventaire | Clip et extraire finv | “finv”, | inventaire tabulaire | | | | données au format tabulaire| paramètres | données (« finv ») | +————————+———————— —+———————–+—————-+—– ——————–+ | Échantillonneur de danger | Préparation du raster | Manipuler le danger | rasters de danger | rasters de danger | | | | rasters | | | +————————+———————— —+———————–+—————-+—– ——————–+ | Échantillonneur de danger | Exemples de rasters | Exemple de raster de danger | rasters de danger,| ensemble de données d’exposition | | | | valeurs | “finv”, DTM | (« expositions ») | +————————+———————— —+———————–+—————-+—– ——————–+ | Variables d’événement | Évaluations des magasins | Ecrire événement | événement dangereux | variables d’événement | | | | probabilités de déposer | probabilités | (« evals ») | +————————+———————— —+———————–+—————-+—– ——————–+ | Conditionnel P | Conditionnel P | Résoudre le conditionnel | “finv”, échec| exposition | | | | probabilités d’exposition| polygones | prob.(“exlike”) | +————————+———————— —+———————–+—————-+—– ——————–+ | Échantillonneur DTM | Échantillonneur DTM | Exemple de raster DTM sur | “finv”, DTM | élévations du sol | | | | géométrie de l’actif | | (« gels ») | +————————+———————— —+———————–+—————-+—– ——————–+ | Validation | Validation | Valider contre | modèle complet | | | | | exigences du modèle | forfait | | +————————+———————— —+———————–+—————-+—– ——————–+
5.1.1. Installer
Cet onglet facilite la création d’un fichier de contrôle à partir des paramètres et de l’inventaire spécifiés par l’utilisateur, ainsi que de fournir des variables de contrôle de fichier générales pour les autres outils de l’ensemble d’outils.
5.1.2. Inventaire
L’onglet inventaire contient un ensemble d’outils pour la construction et la conversion d’inventaires d’actifs d’inondation (“finv”; Section4.1_). Le reste de cette section décrit les outils d’inventaire disponibles.
Aide à la construction d’inventaire
L’outil facultatif « Inventory Construction Helper » aide à construire un modèle d’inventaire des actifs d’inondation à partir d’une géométrie vectorielle dans le cadre de « fonction imbriquée » de CanFlood (Section 4.1_). Une analyse de données supplémentaire en dehors de la plateforme CanFlood est généralement requise pour remplir ces champs.
Bibliothèque de fonctions de vulnérabilité
Pour soutenir la construction de modèles de risque préliminaires, le plug-in CanFlood fournit une collection de bibliothèques de fonctions de vulnérabilité couramment utilisées au Canada. Les utilisateurs doivent étudier attentivement les fonctions de vulnérabilité héritées et leurs méthodes de construction avant de les intégrer dans toute analyse de risque. Au minimum, les fonctions doivent être mises à l’échelle pour tenir compte des transferts spatiaux et temporels.
Compilateur d’inventaire
Le compilateur d’inventaire est un outil simple utilisé pour préparer une couche vectorielle d’inventaire à inclure dans un modèle CanFlood en utilisant le processus suivant :
découpez la couche vectorielle sélectionnée par l’AOI (si elle est sélectionnée dans l’onglet Configuration);
extraire les données non spatiales dans le répertoire de travail au format csv ; et
écrivez l’emplacement du fichier de ce csv et l’Index FieldName dans le fichier de contrôle.
5.1.3. Échantillonneur de danger
L’outil Hazard Sampler génère le jeu de données d’exposition (« expos ») à partir d’un ensemble de rasters d’événements dangereux. En général, ces rasters d’événements dangereux représentent les résultats WSL de certains modèles d’aléas (par exemple HEC-RAS) à des probabilités spécifiques. L’échantillonneur de dangers a deux modes de base :
WSL : échantillons de valeurs raster sur chaque élément (par défaut). Pour les actifs linéaires et polygonaux, cela nécessite que l’utilisateur spécifie une statistique d’échantillonnage.
Inondation : calculez le pourcentage d’inondation de chaque actif (pour la géométrie linéaire et polygonale uniquement). Cela nécessite qu’une couche DTM et un « Seuil de profondeur » soient spécifiés.
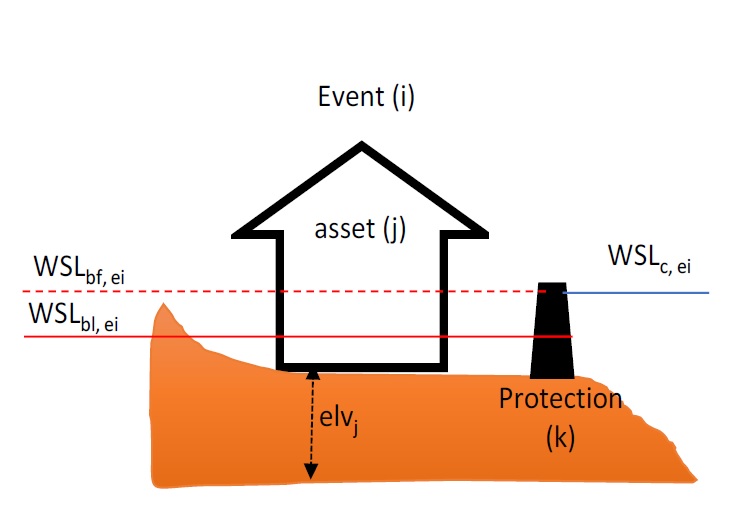
Figure 5-1 : Diagramme de définition du calcul du risque où la ligne pointillée est la valeur WSL de l’événement “ei”
- En utilisant les définitions de la Figure 5-1_, l’exposition WSL d’un événement i à un seul actif j avec une hauteur elv j est calculée comme suit :
expo i,j = WSL bl, ei - elv j
L’échantillonneur de dangers exécute les étapes générales suivantes pour l’ensemble des couches de dangers et la couche d’inventaire fournies par l’utilisateur :
Découpez la couche d’inventaire par l’AOI (si “Project AOI” est spécifié)
Pour chaque couche, échantillonnez la valeur raster ou calculez le pourcentage d’inondation de chaque actif ;
Enregistrez les résultats dans le fichier csv « expos » dans le répertoire de travail et écrivez ce chemin dans le fichier de contrôle ;
Chargez le calque des résultats sur le canevas (facultatif)
Préparation du raster
L’échantillonneur raster s’attend à ce que toutes les couches d’aléas aient les propriétés suivantes :
la couche CRS correspond au projet CRS ;
les valeurs des pixels de couche correspondent à celles des fonctions de vulnérabilité (par exemple, les valeurs sont généralement des mètres);
layer dataProvider est “gdal” (c’est-à-dire que l’outil ne prend pas en charge le traitement des couches Web).
Pour aider les rasters à se conformer à ces attentes, CanFlood inclut une fonction « Préparation des rasters » dans l’onglet « Échantillonneur de risques » avec les outils résumés dans le tableau 5-2_.

Tableau 5-2 : Outils de préparation de raster
+————————-+———————— —+———————–+———————- ———-+ | Nom de l’outil | Poignée | Descriptif | +========================+======================== ===+=======================+====================== ===========+ | Téléchargeur | Autoriser le fournisseur de données | Si le dataProvider de la couche n’est pas “gdal” | | | reconversion | (c’est-à-dire les couches Web), une copie locale de la couche est | | | | dans le répertoire “TEMP” de l’utilisateur. | +————————-+———————— —+———————–+———————- ———-+ | Re-projecteur | Autoriser la reprojection | Si le SCR de la couche ne correspond pas à celui du projet, | | | | l’utilitaire “gdalwarp” est utilisé pour re-projeter la couche.| +————————-+———————— —+———————–+———————- ———-+ | tondeuse AOI | Clip à AOI | Cela utilise l’utilitaire “gdalwarp” pour couper le | | | | raster par la couche de masque AOI. | +————————-+———————— —+———————–+———————- ———-+ | Échelle de valeur | Facteur d’échelle | Pour les ScaleFactors différents de 1,0, cela utilise le Raster| | | | Calculatrice pour mettre à l’échelle les valeurs raster par le | | | | ScaleFactor (utile pour les conversions d’unités simples). | +————————-+———————— —+———————–+———————- ———-+
Après avoir exécuté ces outils, un nouvel ensemble de rasters est chargé dans le projet.
Géométrie d’échantillonnage et type d’exposition
Pour prendre en charge un large éventail d’analyses de vulnérabilité, l’outil Hazard Sampler est capable de développer des variables d’exposition aux WSL et aux inondations à partir des trois types de géométrie de base, comme indiqué dans le tableau 5-3_. Pour les géométries de type ligne et polygone, l’outil nécessite que l’utilisateur spécifie la statistique d’échantillon pour les calculs WSL et un seuil de profondeur pour les calculs de pourcentage d’inondation.
Tableau 5-3 : Configuration de l’échantillonneur de danger par type de géométrie et type d’exposition et [tutoriel pertinent.]
+————————+———————— ———————+—————————– —————–+ | Géométrie | WSL | inondation | | +————————+———————+— ———————+——————–+ | | Paramètres | Exposition | Paramètres | Exposition | +========================+======================== +====================+========================+=== ==================+ | pointe | Par défaut | WSL | Par défaut | WSL 1 | | | [Tutoriel 2a] | | [Tutoriel 1a] | | +————————+———————— +——————–+————————-+— —————–+ | Ligne4 4 | Exemple de statistique | Statistiques WSL | % inondation, | % inondation | | | 3, 5 | | Seuil de profondeur 2 | | | | | | [Tutoriel 4b] | | +————————+———————— +——————–+————————-+— —————–+ | Polygone 4 | Exemple de statistique | Statistiques WSL | % inondation, | % inondation | | | 3 | | Seuil de profondeur 2 | | | | | | [Tutoriel 4a] | | +————————+———————— +——————–+————————-+— —————–+ | 1. Pour appliquer une profondeur de seuil, les valeurs f_elv peuvent être manipulées manuellement. Les valeurs d’exposition WSL sont converties en | | exposition binaire (c’est-à-dire inondée ou non inondée) par le modèle de risque (L1). | | 2. Nécessite qu’un raster DTM soit spécifié dans l’onglet « Échantillonneur DTM ». Les outils de modèle s’attendent à ce que l’inventaire des actifs (“finv”) | | contiennent une colonne “f_elv” avec toutes les valeurs nulles et parameter.felv=”datum”. Respecte les valeurs de cellule raster NULL comme | | pas inondé. | | 3. Ignore les valeurs NoData lors du calcul des statistiques. | | 4. Les valeurs M et Z ne sont pas prises en charge. | | 5. Lève une erreur « les fonctionnalités de la couche d’entrée n’ont pas pu être mises en correspondance » lorsque des valeurs nulles sont rencontrées. Cette erreur | | est sûr d’ignorer. | +————————-+———————— -+——————–+————————+– —————–+
5.1.4. Variables d’événement
L’outil « Store Evals » des variables d’événement stocke les probabilités d’événement spécifiées par l’utilisateur dans l’ensemble de données des variables d’événement (« evals »). L’outil Hazard Sampler doit être exécuté en premier pour remplir le tableau Event Variables.
Remarques et limites
Les éléments suivants s’appliquent aux variables d’événement et aux outils connectés :
Les modules Risque (L1 et L2) nécessitent au moins 3 événements probabilités d’événements uniques.
5.1.5. Conditionnel P
Pour incorporer l’échec de la défense (section 1.4_), les modèles CanFlood « Risk (L1) » et « Risk (L2) » s’attendent à un ensemble de données sur les probabilités d’exposition résolues (« exlikes ») qui spécifie la probabilité d’exposition conditionnelle de chaque actif à chaque défaillance de danger. raster. L’outil « Conditionnel P » fournit une conversion d’une collection de polygones et de rasters de zone d’influence de défaillance (c. Pour chaque événement d’échec conditionnel, l’outil « P conditionnel » s’attend à ce que l’utilisateur fournisse une paire composée des couches suivantes :
Raster de WSL qui serait réalisé en cas d’échec
Couche vectorielle avec des caractéristiques surfaciques indiquant l’étendue et la probabilité de défaillances d’éléments pendant l’événement dangereux (« polygones de défaillance »). Ces caractéristiques peuvent ne pas se chevaucher (conditions simples) ou se chevaucher (conditions complexes) comme expliqué ci-dessous.
L’utilisateur peut spécifier jusqu’à huit appariements événement-raster/conditionnelle-exposition-probabilité-polygone avec l’interface graphique.
CanFlood distingue les polygones de probabilité d’exposition conditionnelle « complexe » et « simple » en fonction du chevauchement géométrique de leurs caractéristiques, comme résumé dans le tableau 5-4_ et illustré dans la figure 5-2_.
Tableau 5-4 : Résumé du traitement du polygone de probabilité d’exposition conditionnelle.
+——————-+——————-+———- ———————————-+—————– ——+ | Type | Caractéristiques | Traitement | Exemple (Figure 5-5) | +===================+==================+========== ================================+================= ======+ | trivial | aucun | Échec non pris en compte, non résolu | n/a | | | | probabilités d’exposition (“exlikes”) | | | | | requis | | +——————-+——————-+———- ———————————-+—————– ——+ | simple | ne se chevauchent pas | L’outil “P conditionnel” rejoint le | f2, f3 | | | | valeur attributaire de l’entité surfacique | | | | | sur chaque actif pour générer résolu | | | | | probabilités d’exposition (“exlikes”). | | +——————-+——————-+———- ———————————-+—————– ——+ | complexe | chevauchement | voir ci-dessous | f1 | +——————-+——————-+———- ———————————-+—————– ——+
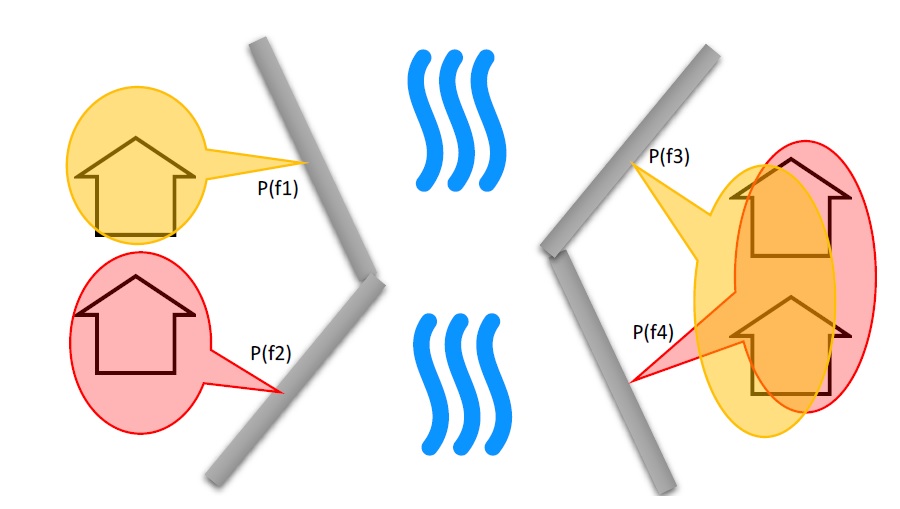
Figure 5-2 : Simple [gauche] vs. Complexe [droite] diagramme conceptuel de polygone de probabilité d’exposition conditionnelle montrant une seule couche avec quatre entités.
Pour les conditions complexes, « Conditionnel P » fournit deux algorithmes pour résoudre les polygones de défaillance qui se chevauchent jusqu’à une probabilité de défaillance unique (pour un actif donné sur un raster de défaillance donné) sur la base de deux hypothèses alternatives pour la relation mécanique entre les mécanismes de défaillance résumés dans le tableau 5- 5.
Tableau 5-5 : Algorithmes de résolution des polygones de probabilité d’exposition conditionnelle pour les conditions complexes
+——————-+—————————— ——————————–+ | Relation | Résumé de l’algorithme | +===================+============================= =================================+ | Mutuellement exclusif| .. image :: /_static/algorithm_summary_1.jpg | | | | +——————-+——————-+———- ——————————–+ | Indépendant | .. image :: /_static/algorithm_summary_2.jpg | | 1 | | +——————-+——————-+———- ——————————–+ | Où P(X) est la probabilité de défaillance résolue pour un seul actif sur un | | événement et P(i) est la valeur probable de défaillance échantillonnée à partir d’un polygone de défaillance | | caractéristique. | | | | 1) Bedford et Cooke (2001) | +——————-+——————-+———- ——————————–+
5.1.6. Échantillonneur DTM
L’outil DTM Sampler utilise le même module que Hazard Sampler pour échantillonner les valeurs de raster DTM sur chaque actif fourni dans la couche vectorielle d’inventaire. Cet outil génère l’ensemble de données d’élévation du sol (« gels ») et écrit la référence correspondante dans le fichier de contrôle. Ce jeu de données est requis par tout modèle dans lequel les paramètres de hauteur ou d’élévation des données d’inventaire (« finv ») sont spécifiés par rapport au sol (felv=”ground”).
5.1.7. Validation
L’outil de validation effectue une série de vérifications sur le fichier de contrôle spécifié pour s’assurer que les exigences de données du modèle spécifié sont satisfaites. Si les contrôles sont satisfaits, l’indicateur de validation correspondant est défini dans le fichier de contrôle, permettant à l’outil de modèle de s’exécuter.
5.2. Modèle
L’ensemble d’outils « Modèle » fournit une interface graphique pour faciliter l’accès aux 3 modèles de risque d’inondation de CanFlood. Les modèles L2 de CanFlood sont divisés entre l’exposition et le risque pour faciliter les applications personnalisées (celles-ci peuvent être liées à l’aide de la case à cocher « Exécuter le modèle de risque (L2) »). Les onglets suivants sont implémentés dans l’ensemble d’outils de modèle de CanFlood :
Configuration : chemins de fichiers, descriptions d’exécution et paramètres facultatifs utilisés par tous les outils de modèle ;
Risque (L1) : Analyse de probabilité d’inondation ;
Impacts (L2) : Première partie des modèles L2, exposition par événement calculée avec des fonctions de vulnérabilité ;
Risque (L2) : deuxième partie des modèles L2, valeur attendue de tous les impacts de l’événement ;
Risque (L3) : modèle de recherche SOFDA
Exécutions par lots
Pour faciliter les simulations par lots pour les utilisateurs avancés, tous les modules de modélisation CanFlood ont des exigences de dépendance réduites (par exemple, l’API QGIS n’est pas requise).
Résumé des paramètres
Le tableau suivant résume les paramètres pertinents pour l’ensemble d’outils de modèle de CanFlood qui peuvent être spécifiés dans le fichier de contrôle :
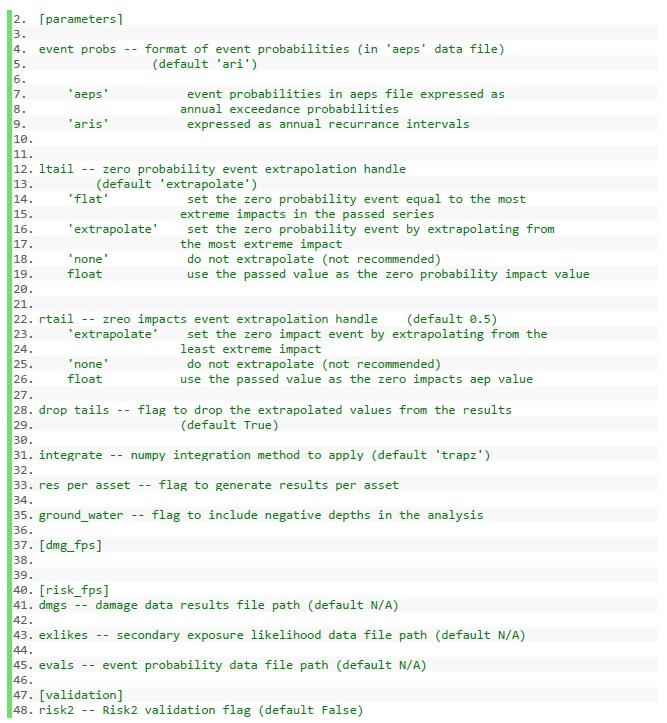
Certains d’entre eux peuvent être configurés avec l’interface utilisateur de l’ensemble d’outils « Build » de CanFlood, tandis que d’autres doivent être spécifiés manuellement dans le fichier de contrôle.
5.2.1. Risque (L1)
L’outil de risque L1 de CanFlood fournit une évaluation préliminaire du risque d’inondation avec une exposition binaire, comme indiqué dans la section 3.1_. Cet outil prend également en charge les entrées de probabilité conditionnelle pour incorporer les défaillances de la protection contre les inondations. Le tableau 5-6_ résume les exigences d’entrée pour le modèle de risque (L1), qui sont généralement préparées à l’aide des outils « Build » (Figure 3-1_).
Tableau 5-6 : Exigences relatives à l’emballage du modèle CanFlood de risque (N1).
+————————+———————— —+———————–+—————-+—– ——————–+ | Nom | Descriptif | Outil de construction | Code | Exig. | +========================+======================== ===+=======================+================+===== ====================+ | Fichier de contrôle | Chemins d’accès aux fichiers de données et | Démarrer le fichier de contrôle | | oui | | | paramètres | | | | +————————+———————— —+———————–+—————-+—– ——————–+ | Inventaire | Inventaire tabulaire des actifs | Compilateur d’inventaire | finv | oui | | | données | | | | +————————+———————— —+———————–+—————-+—– ——————–+ | Exposition | WSL ou %inondé | Échantillonneur de danger | expositions | oui | | | données d’exposition | | | | +————————+———————— —+———————–+—————-+—– ——————–+ | Probabilités d’événement | Probabilité de chacun | Variables d’événement | évaluations | oui | | | événement dangereux | d’applicable | | | +————————+———————— —+———————–+—————-+—– ——————–+ | Probabilités d’exposition | Probabilité conditionnelle | Conditionnel P | aime | pour l’échec | | | de chaque actif réalisant | | | | | | le raster d’échec | | | | +————————+———————— —+———————–+—————-+—– ——————–+ | Élévations du sol | Élévation du sol à | Échantillonneur DTM | gels | pour fev=sol | | | chaque actif | | | | +————————+———————— —+———————–+—————-+—– ——————–+
Le module Risk (L1) peut être utilisé pour estimer une gamme de mesures simples grâce à une utilisation créative des champs d’inventaire d’actifs (“finv”) discutés dans la section 4.1_. Lorsque le facteur « échelle » est défini sur 1, « hauteur » sur zéro et qu’aucune probabilité conditionnelle n’est utilisée (typique pour l’analyse d’inondation), la plupart des calculs deviennent triviaux car le résultat est simplement les valeurs d’impact fournies par les « expos » table (à l’exception du calcul de la valeur attendue).
Les résultats fournis par cet outil sont résumés dans le tableau suivant :
Tableau 5-7 : Résumé du fichier de sortie du modèle de risque.
+——————-+———–+—————– ———————————-+ | Nom de sortie | Code | Descriptif | +===================+===========+================= ====================================+ | résultats totaux | r_ttl | tableau de la somme des impacts (pour tous les actifs) par événement | | | | et valeur attendue de tous les événements (EAD) | +——————-+———–+—————– ———————————-+ | résultats par actif | r_passet | tableau des impacts par actif par événement et attendu | | | | valeur de tous les événements par actif | +——————-+———–+—————– ———————————-+ | courbe de risque | | tracé de la courbe de risque des impacts totaux | +——————-+———–+—————– ———————————-+
5.2.2. Impacts (L2)
L’outil « Impacts (L2) » de CanFlood est conçu pour effectuer une évaluation déterministe des dommages dus aux inondations « classique » basée sur des objets à l’aide de courbes de vulnérabilité, de hauteurs d’actifs et de valeurs WSL pour estimer les impacts des inondations de plusieurs événements. Cet outil calcule les impacts sur chaque actif de chaque événement dangereux (si le raster WSL fourni a été réalisé). « Impacts (L2) » ne prend pas en compte ou ne prend pas en compte les probabilités d’événements (conditionnelles ou autres) car elles sont traitées dans le module Risque (L2) (voir Section 5.2.3_). Les exigences du package modèle sont résumées dans le tableau suivant :
Tableau 5-8 : Exigences relatives au package du modèle Impacts (L2).
+————————+———————— —+———————–+—————-+—– ——————–+ | Nom | Descriptif | Outil de construction | Code | Exig. | +========================+======================== ===+=======================+================+===== ====================+ | Fichier de contrôle | Chemins d’accès aux fichiers de données et | Démarrer le fichier de contrôle | | oui | | | paramètres | | | | +————————+———————— —+———————–+—————-+—– ——————–+ | Inventaire | Inventaire tabulaire des actifs | Compilateur d’inventaire | finv | oui | | | données | | | | +————————+———————— —+———————–+—————-+—– ——————–+ | Exposition | WSL ou %inondé | Échantillonneur de danger | expositions | oui | | | données d’exposition | | | | +————————+———————— —+———————–+—————-+—– ——————–+ | Élévations du sol | Élévation du sol à | Échantillonneur DTM | gels | pour | | | chaque actif | | | fev=sol | +————————+———————— —+———————–+—————-+—– ——————–+ | Fonction de vulnérabilité | Collection de fonctions | Vulnérabilité | courbes | oui | | Ensemble | concernant l’exposition à | Bibliothèque de fonctions | | | | | impact | | | | +————————+———————— —+———————–+—————-+—– ——————–+
Les sorties des impacts (L2) sont résumées dans le tableau suivant, où seule la sortie « dmgs » est requise par le modèle de risque (L2) :
Tableau 5-9 : Résultats des impacts (L2).
+———————-+———–+————— ————————————+ | Nom de sortie | Code | Descriptif | +=====================+===========+=============== ======================================+ | impacts totaux | dmg | impacts totaux calculés pour chaque actif | +———————-+———–+————— ————————————+ | élargi | dmgs_expnd| impacts complets calculés sur chaque imbriqué | | impacts des composants | | fonction de chaque actif (voir ci-dessous) | +———————-+———–+————— ————————————+ | calcul des impacts | bdmg_smry | classeur résumant les composants du | | résumé | | calcul d’impact (voir ci-dessous) | +———————-+———–+————— ————————————+ | profondeurs | profondeurs_df | valeurs de profondeur calculées pour chaque actif | +———————-+———–+————— ————————————+ | histogramme d’impact | | graphique récapitulatif des valeurs d’impact total par actif | | résumé | | | +———————-+———–+————— ————————————+ | boîte à moustaches d’impact | | graphique récapitulatif des valeurs d’impact total par actif | +———————-+———–+————— ————————————+
Fonctions imbriquées
Pour faciliter les actifs complexes (par exemple une maison vulnérable aux dommages structurels et de contenu), Impacts (L2) prend en charge les fonctions de vulnérabilité composite paramétrées avec les 4 attributs clés (“tag”, “scale”, “cap”, “elv”) avec le “ Le préfixe f” et le numérateur “nestID” (par exemple f0, f1, f2, etc.) discutés dans la section 4.1. De cette façon, CanFlood peut simuler une fonction de vulnérabilité complexe en combinant l’ensemble de fonctions de composants simples pour estimer les dommages causés par les inondations. Un exemple d’entrée dans l’inventaire des actifs (« finv ») pour une maison unifamiliale peut ressembler à :
+——-+——–+———-+——–+———+— —–+——–+———-+———+ | xid | f0_tag | f0_échelle | f0_cap | f0_elv | f1_cap | f1_elv | f1_échelle | balise f1 | +——-+——–+———-+——–+———+— —–+——–+———-+———+ | 14879 | BA_S | 117,99 | 91300 | 11.11 | 20000 | 11.11 | 117,99 | BA_C | +——-+——–+———-+——–+———+— —–+——–+———-+———+
Où BA_S correspond à une fonction de vulnérabilité pour estimer le nettoyage/la réparation structurelle, et BA_C estime les dommages au contenu du ménage (tous deux mis à l’échelle par la surface de plancher). Des colonnes fX supplémentaires pourraient être ajoutées en tant que fonctions de vulnérabilité des composants pour les sous-sols, les garages, etc. Chacun des groupes de quatre attributs clés est appelé « fonction imbriquée », où la collection de fonctions imbriquées comprend la fonction de vulnérabilité complète d’un actif.
Impacts (L2) calcule l’impact d’un événement ei sur un seul actif j à partir de sa collection de fonctions de vulnérabilité imbriquées k comme :
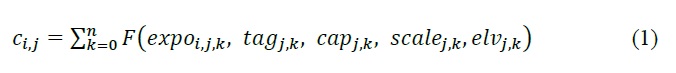
Où chaque fonction de vulnérabilité imbriquée est paramétrée par les éléments suivants fournis dans le fichier de contrôle (Section 4.1_) :
tag : variable reliant l’actif à la courbe de vulnérabilité correspondante dans l’ensemble de courbes de vulnérabilité (“curves”) ;
cap : plafond de valeur maximum placé sur le résultat de la courbe de vulnérabilité ;
échelle : valeur d’échelle appliquée au résultat de la courbe de vulnérabilité ;
elv : distance verticale de la valeur d’exposition.
Et les éléments suivants fournis dans l’ensemble de données d’exposition (« expos ») :
expo : ampleur de l’exposition aux inondations échantillonnée au niveau de l’actif.
La routine « Impacts (L2) » calcule d’abord les impacts de chaque fonction imbriquée, puis met à l’échelle les valeurs, puis plafonne les valeurs, avant de combiner toutes les valeurs imbriquées pour obtenir l’impact total pour un actif donné.
En règle générale, l’ensemble de données d’exposition (« expos ») est construit avec l’outil « Hazard Sampler » (Section5.1.3_) et contient un ensemble de WSL échantillonnés pour chaque actif et chaque événement. Cependant, les seules exigences sur le fichier “expos” sont qu’il corresponde aux attentes des fonctions de vulnérabilité référencées par le paramètre “curves” (Section 4.3_).
Eau souterraine
Pour améliorer les performances, Impacts (L2) n’évalue que les actifs avec des profondeurs positives (lorsque “ground_water”=False) et des profondeurs réelles. En spécifiant “ground_water”= True , les profondeurs négatives (dans la profondeur minimale trouvée dans toutes les fonctions de dommages chargées) peuvent être incluses dans le calcul.
Mesures d’atténuation au niveau de l’objet
Le modèle « Impacts (L2) » facilite la modélisation des réductions d’exposition induites par des mesures d’atténuation au niveau de l’objet (ou de la propriété) (PLPM) telles que les clapets anti-retour ou la mise en sac de sable. L’effet réel de telles interventions sur l’exposition hydraulique des bâtiments ou des propriétés est complexe et peut être influencé par : 1) la nature active vs passive du PLPM ; 2) l’heure et l’heure d’avertissement du jour ou de l’année (pour les PLPM actives) ; 3) chargement hydraulique sur le PLPM ; 4) qualité d’installation du PLPM ; 5) expérience ou erreur de l’opérateur (pour les PLPM actives) ; 6) entretien du PLPM. CanFlood ne considère pas cette complexité ; au lieu de cela, CanFlood facilite l’approximation de l’utilisateur grâce à des seuils simples, des facteurs d’échelle et des valeurs d’addition. Ce paramétrage doit être fourni pour chaque actif dans la couche vectorielle d’inventaire (« finv ») avec la Section5.2.
Seuil inférieur (mi_Lthresh) : Toutes les profondeurs inférieures généreront une valeur d’impact de zéro.
Seuil supérieur (mi_Uthresh) : Toutes les profondeurs au-dessus de ce seuil n’auront PAS de facteurs d’échelle d’impact ou de valeurs d’addition d’impact appliquées.
Facteur d’échelle d’impact (mi_iScale) : pour les profondeurs inférieures au « seuil supérieur », les valeurs d’impact seront mises à l’échelle par ce facteur.
Valeur d’ajout d’impact (mi_ iVal) : pour les profondeurs inférieures au « seuil supérieur », les valeurs d’impact se verront ajouter cette valeur.
Sorties supplémentaires
Pour une analyse avancée, les utilisateurs peuvent sélectionner l’option « dmgs_expnd » pour afficher les impacts complets calculés sur chaque fonction imbriquée de chaque actif. Ce fichier de données volumineux et intermédiaire fournit les valeurs d’impact brutes, mises à l’échelle, plafonnées et résolues 2 pour chaque actif et chaque fonction imbriquée. Cela peut être utile pour l’analyse de données supplémentaire et le dépannage, mais n’a pas besoin d’être généré pour les routines de modèle (c’est-à-dire qu’il est fourni à titre d’information uniquement).
Une autre sortie facultative est fournie via la fonction “bdmg_smry” et le paramètre correspondant qui résume les résultats de chaque étape ou routine dans le module “Impacts (L2)”. Le premier onglet de la feuille de calcul, « _smry », montre les impacts totaux pour chaque événement à chaque routine dans le module. Le groupe d’onglets suivant résume les impacts calculés sur chaque ftag pour la routine correspondante (par exemple, “brut”, “échelle”, “plafonné”, “dmg”, “mi_Lthresh”, “mi_iScale”, “mi_iVal”). Deux onglets supplémentaires sont fournis pour résumer les calculs de la routine de plafonnement (c’est-à-dire “cap_cnts” et “cap_data”).
5.2.3. Risque (L2)
L’outil « Risk (L2) » de CanFlood est conçu pour effectuer une évaluation déterministe des risques d’inondation « classique » basée sur des objets en utilisant des estimations d’impact et des probabilités pour calculer une mesure de risque annualisée. Au-delà de ce modèle de risque classique, le « Risque (L2) » facilite également les estimations des risques qui intègrent des événements d’aléa conditionnels, comme la rupture d’une digue lors d’une inondation de 100 ans. Cela peut être conceptualisé avec le cadre « source-voie-récepteur » de Sayers (2012) comme le montre la figure 5-3_, où :
Source : prédiction WSL (au format raster) pour les niveaux derrière la défense (par exemple digue) d’un événement avec une vraisemblance quantifiée.
Pathway : L’élément d’infrastructure séparant les récepteurs (c’est-à-dire les actifs) de la prédiction WSL brute. En règle générale, il s’agit d’une digue, mais il peut s’agir de n’importe quel élément pour lequel la probabilité de « défaillance » et le WSL peuvent être quantifiés (p. ex. vannes d’évacuation des eaux pluviales, pompes à eaux pluviales).
Récepteur : Biens vulnérables aux inondations où l’emplacement et les variables pertinentes sont catalogués dans l’inventaire et la vulnérabilité est quantifiée avec une fonction profondeur-dommages.
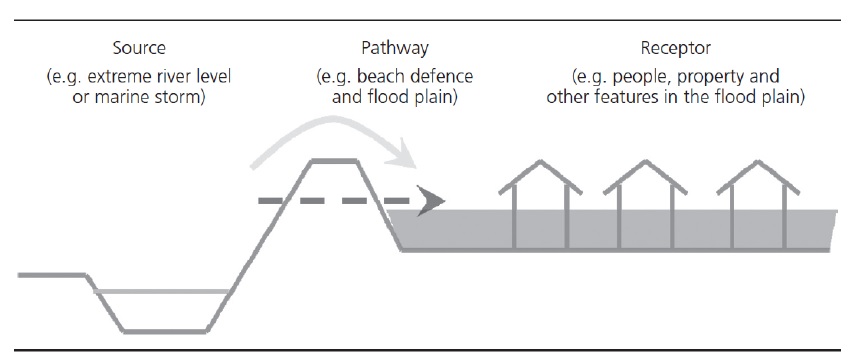
Figure 5-3 : Framework source-chemin-récepteur de Sayers (2012).
Les exigences du package modèle pour l’outil Risk (L2) sont résumées dans le tableau suivant :
Tableau 5-10 : Exigences de package de modèle de risque (L2).
+————————+———————— —+———————–+—————-+—– ——————–+ | Nom | Descriptif | Outil de construction | Code | Exig. | +========================+======================== ===+=======================+================+===== ====================+ | Fichier de contrôle | Chemins d’accès aux fichiers de données et | Démarrer le fichier de contrôle | | oui | | | paramètres | | | | +————————+———————— —+———————–+—————-+—– ——————–+ | Probabilités d’événement | Probabilité de chacun | Variables d’événement | évaluations | oui | | | événement dangereux | | | | +————————+———————— —+———————–+—————-+—– ——————–+ | Probabilités d’exposition | Probabilité conditionnelle de| Conditionnel P | aime | pour l’échec | | | chaque actif réalisant le | | | | | | raster d’échec | | | | +————————+———————— —+———————–+—————-+—– ——————–+ | Impacts totaux | Résultats des impacts | S/O | dmg | oui | | | (L2) modèle | | | | +————————+———————— —+———————–+—————-+—– ——————–+
Les résultats fournis par cet outil sont résumés dans le Tableau 5-7_.
Événements sans échec
Une application simple du modèle « Risque (L2) » est une zone d’étude sans infrastructure de protection contre les inondations significative (par exemple, une plaine inondable sans digues), comme dans le didacticiel 2a (Section 6.2_). Dans ce cas, chaque événement dangereux a une seule probabilité et un seul raster et les résultats de l’outil « Impacts (L2) » doivent simplement être intégrés pour produire la métrique de risque annualisée. La principale mesure de risque calculée par CanFlood est la valeur attendue des impacts des inondations E[X] (également appelé Dégâts annuels attendus (EAD), ou Dégâts annuels moyens (AAD), ou Perte annualisée) et est défini pour événements discrets tels que :

Où x i est l’impact total de l’événement i et p i est la probabilité que cet événement se produise. Alors que les modèles d’inondation discrétisent les événements par nécessité (par exemple, 100 ans, 200 ans), les inondations réelles génèrent des variables d’aléa continues (par exemple, 100 à 200 ans). Par conséquent, la forme continue de l’équation précédente est requise :
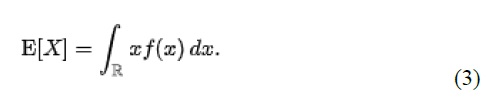
Où f(x) est une fonction décrivant la probabilité de tout événement x (c’est-à-dire la fonction de densité de probabilité) (USACE 1996). Pour s’aligner sur les expressions typiques de probabilité de débit courantes dans l’analyse des risques d’inondation, l’équation précédente est manipulée davantage pour :
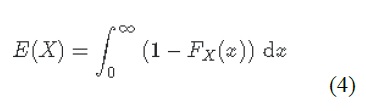
Où Fx(x) est la probabilité cumulée de tout événement x (par exemple, fonction de distribution cumulée). Reconnaissant que le complément de Fx(x) est la probabilité de dépassement annuel (AEP) (la probabilité de réaliser un événement de magnitude x ou plus), cette équation donne la « courbe de risque » classique commune dans les évaluations des risques d’inondation montrées dans la figure 5-4_.
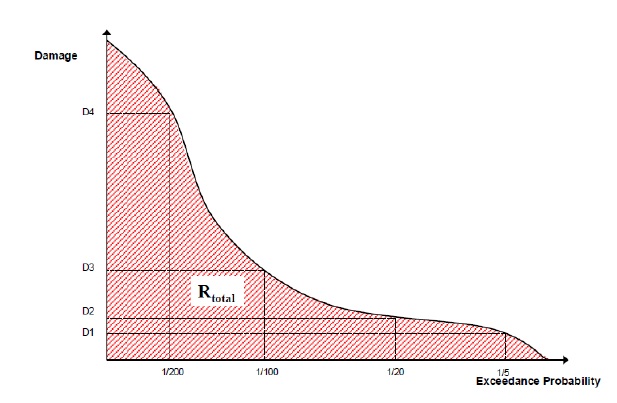
Figure 5-4 : Courbe de probabilité de dommages de Messner (2007).
L’algorithme suivant est implémenté dans les modèles « Risk (L1) » et « Risk (L2) » de CanFlood pour calculer la valeur attendue :
Assembler une série d’AEP et d’impacts totaux pour chaque événement ;
Extrapolez cette série avec les descripteurs d’extrapolation fournis par l’utilisateur (« rtail » et « ltail ») ;
Utilisez la méthode numpy integration spécifiée par l’utilisateur pour calculer l’aire sous la série.
Le même algorithme est utilisé pour calculer la valeur totale attendue sur tous les actifs et pour la valeur attendue des actifs individuels (si “res_per_asset”=True).
Événements avec échec
Lors de la résolution d’un événement dangereux avec une défaillance, CanFlood combine la valeur attendue (E(X)) de chaque événement de défaillance associé avec celle d’un événement de base « sans échec » pour obtenir la valeur totale attendue de l’événement requise par l’équation de mesure du risque ( formule 4). Pour fournir une flexibilité dans les exigences de données d’une analyse de fiabilité de la défense, CanFlood distingue deux dimensions d’analyse d’événement de défaillance en fonction de la géométrie des polygones de probabilité d’exposition conditionnelle fournis (« polygones de défaillance ») et du nombre d’événements de défaillance, comme résumé dans la figure 5-5_. La complexité des « polygones de défaillance » est abordée dans la section 5.1.5 et est résolue dans l’ensemble de données des probabilités d’exposition résolues (« exlikes ») en calculant une probabilité d’exposition unique pour chaque événement de défaillance associé (Figure 5-5_ « b1 » et « b2 » dans « » f1”).
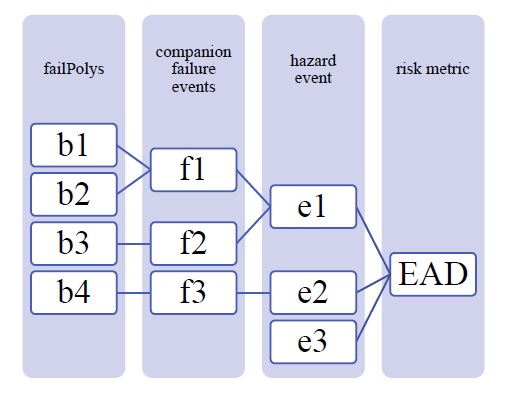
Figure 5-5 : Exemple de diagramme montrant trois événements dangereux, un sans défaillance (e3), un avec des événements de défaillance simples (e2) et un avec des événements de défaillance complexes (e1), et deux événements de défaillance associés avec un simple (f2, f3) et le autre (f1) avec des polygones de probabilité d’exposition conditionnelle complexes (polygones de défaillance).
Le tableau 5-11_ résume le traitement des événements dangereux en fonction du nombre d’événements de défaillance attribués à chacun.
Tableau 5-11 : Traitement des événements dangereux par nombre d’événements de défaillance.
+————+———-+————————– —-+————————+ | Type | Compter | Traitement 1 | Exemple (Figure 5-5_) | +===========+==========+========================== ====+=========================+ | trivial | 0 | E(X)échec=0 | e3 | | | | E(X)nofail de l’équation 2 | | +————+———-+————————– —-+————————+ | simple | 1 | “max” ou “mutEx” | e2 | +————+———-+————————– —-+————————+ | complexe | >1 | “max”, “mutEx” ou “indep” | e1 | +————+———-+————————– —-+————————+ | 1) Voir Tableau 5-12_ | +—————————————————————- —————————–+
Événements avec échec complexe
Le tableau 5-12_ résume les algorithmes mis en œuvre dans CanFlood pour calculer la valeur attendue pour les événements dangereux avec plus d’un événement de défaillance associé, c’est-à-dire des événements de défaillance « complexes ».
Table5-12 : Algorithmes de valeur attendue pour les événements de défaillance.
+———————+———–+—————- ————————————————– –+ | nom | Compter | résumé | +=====================+==========+================ ================================================== ==+ | Maximum modifié | max | .. image :: /_static/toolsets_model_table_5_12_eq_1.jpg | | | | | +———————+———–+—————- ————————————————– –+ | mutuellement exclusif | mutEx | .. image :: /_static/toolsets_model_table_5_12_eq_2.jpg | | | | | +———————+———–+—————- ————————————————– –+ | Indépendant | indépendant | a) Construire une matrice de toutes les combinaisons possibles d’événements de défaillance | | | | (positifs=1 et négatifs=0) | | | | | | | | b) Remplacer les valeurs matricielles par P et (1-P) | | | | | | | | c) Multipliez l’ensemble pour obtenir la probabilité de la combinaison | | | | (P comb) | | | | | | | | d) Multipliez P comb par l’impact maximum des événements dans | | | | l’ensemble pour obtenir l’impact de la combinaison (C comb) | | | | | | | | e) .. image :: /_static/toolsets_model_table_5_12_eq_3.jpg | +———————+———–+—————- ————————————————– –+ | P(o) = 1-somme(C i) | +—————————————————————- ————————————————– –+
5.2.4. Risque (L3)
Bryant (2019) a développé le cadre de modèle d’évaluation dynamique des dommages causés par les inondations (SOFDA) basé sur des objets stochastiques pour simuler le risque d’inondation au fil du temps à l’aide des courbes de l’Alberta et d’une prévision de réaménagement résidentiel. L’élaboration du cadre a été motivée par le désir de quantifier les avantages des règlements sur les risques d’inondation (RFH) et d’aider à intégrer la dynamique du risque dans la prise de décision. SOFDA quantifie le risque d’inondation d’un actif à l’aide de fonctions de dommages directs et de probabilité de profondeur. De cette manière, le risque d’inondation peut être quantifié (par exemple monétisé) à des résolutions spatiales fines pour une aide à la décision robuste.
SOFDA dispose des capacités suivantes :
Estimer la réduction de la vulnérabilité de la réglementation sur les risques d’inondation ;
Estimer la réduction de la vulnérabilité des mesures de protection au niveau de la propriété ;
Estimer l’influence de l’élévation des éléments endommagés (p. ex. l’élévation des chauffe-eau);
Simuler les changements dans la typologie des bâtiments pertinents provoqués par le réaménagement (par exemple, des maisons plus grandes avec des sous-sols plus profonds);
Modélisation dynamique et flexible de nombreux composants du modèle (par exemple, des chauffe-eau plus chers)
Fournir une certaine quantification de l’incertitude (c.-à-d. modélisation stochastique);
Fournir des résultats détaillés pour faciliter l’analyse des mécanismes sous-jacents.
Pour plus d’informations et de conseils, voir `Annexe B <appendix_b_>`__.
5.3. Résultats
L’ensemble d’outils « Résultats » est une collection d’outils pour aider l’utilisateur à effectuer une analyse et une visualisation des données secondaires sur les modèles CanFlood. Le reste de cette section décrit la fonction des outils de cet ensemble d’outils.
5.3.1. Rejoindre Géo
Cet onglet fournit un outil pour joindre les résultats des risques non spatiaux sur la géométrie de l’inventaire pour le post-traitement spatial. Une version de base de cet outil peut être exécutée automatiquement par les outils “Risk (L1)” et “Risk (L2)”. Dans l’onglet « Rejoindre Geo », l’utilisateur peut effectuer une personnalisation supplémentaire de ces calques, notamment en appliquant des styles de calques pré-emballés.
5.3.2. Diagramme de risque
Cet onglet contient plusieurs outils pour générer des tracés non spatiaux sur un seul scénario de modèle. Les tracés générés sur cet onglet extraient tous les informations de style du groupe “[tracé]” du fichier de contrôle et les données de résultats du groupe “[results_fp]”. Les graphiques sont disponibles dans les deux formats de courbe de risque standard :
IRA vs. Impacts
Impacts vs AEP
Voir Section6.3.3_ pour des exemples.
Total de la parcelle
Cet outil génère un graphique simple des résultats totaux. Une version de base de cet outil peut être exécutée automatiquement à partir des outils “Risk (L1)” et “Risk (L2)” pour plus de commodité.
Pile de tracé
Cet outil génère des courbes de risque montrant les contributions totales de chaque fonction de vulnérabilité composite discutée dans la section 4.1_ sur un seul graphique.
Scission d’échec du tracé
Cet outil génère une courbe de risque composite montrant les résultats totaux avec une deuxième courbe montrant la contribution de la partie « non-échec » de chaque événement (c.
5.3.3. Comparer/Combiner
Cet onglet fournit deux outils pour combiner ou comparer plusieurs modèles CanFlood au sein d’une même analyse. Par exemple, une analyse des risques d’inondation tenant compte des pertes agricoles et des dommages aux bâtiments résidentiels devrait généralement construire deux modèles distincts (c’est-à-dire des fichiers de contrôle distincts) et combiner les résultats à la fin pour comprendre le risque total. Alternativement, une analyse peut souhaiter comparer deux alternatives d’atténuation.
Comparer
L’outil de comparaison collecte l’ensemble de données des résultats totaux (“r_ttl”) et les paramètres de l’ensemble de fichiers de contrôle spécifiés et produit deux sorties de comparaison :
Comparaison du fichier de contrôle : génère un fichier de données contenant les paramètres de chaque fichier de contrôle sélectionné et une dernière colonne indiquant si le paramètre varie dans l’ensemble. Cela peut être utile pour indiquer ce qui sépare deux modèles CanFlood.
Comparaison de tracés : crée un tracé de courbe de risque comparant l’ensemble de données de résultats totaux (“r_ttl”) de tous les fichiers de contrôle sélectionnés. Les valeurs de tracé par défaut sont extraites du fichier de contrôle spécifié dans l’onglet « Configuration ».
Combiner
L’outil de combinaison collecte l’ensemble de données des résultats totaux (« r_ttl ») et les paramètres du fichier de contrôle principal (de l’onglet « Configuration ») pour générer deux types de sorties :
Scénario composite : sélectionnez cette option lors de l’exécution de l’outil « Combiner » pour générer un nouveau fichier de contrôle composite et un fichier de résultats « r_ttl » pour une analyse plus approfondie.
Plot combiner : crée une courbe de risque empilée montrant la contribution au risque total de chaque fichier de contrôle sélectionné.
5.3.4. Analyse avantages-coûts
Cet onglet fournit deux outils pour prendre en charge les calculs avantages-coûts de base couramment utilisés dans les évaluations des options d’atténuation des inondations. L’analyse avantages-coûts (ACC) est un processus complexe discuté ailleurs (Merz et al. 2010 ; Smith et al. 2016 ; IWR et USACE 2017) qui comporte de nombreux défis et lacunes lorsqu’il est appliqué aux décisions concernant l’atténuation des inondations (O’Connell et O’Donnell 2014, Hosein 2016). En bref, l’ACB compare la valeur actuelle nette des coûts d’une intervention (par exemple, la construction, l’entretien) aux avantages ou aux pertes d’inondations évitées grâce à l’intervention. Grâce à l’application d’un taux d’actualisation dans ces calculs de valeur actuelle nette, les BCA sont sensibles au calendrier ou à l’accumulation des avantages et des coûts. Un flux de travail typique dans CanFlood mettant en œuvre BCA est fourni ci-dessous :

Pour prendre en charge des calculs BCA simples, l’onglet « BCA » de CanFlood fournit les outils suivants :
Copier le modèle BCA
Cet outil copie le modèle CanFlood BCA (“cf_bca_template_01.xlsx”, voir ci-dessous), qui a un onglet “smry” et “data”, et remplit l’onglet “smry” avec les métadonnées du fichier de contrôle principal. Ce fichier .xlsx fournit un modèle générique pour la saisie des séries chronologiques des coûts et des avantages du projet et le calcul des valeurs financières récapitulatives, telles que le rapport avantages-coûts, à l’aide des formules intégrées d’EXCEL. Le classeur contient des « notes » Excel et implémente les styles suivants pour guider les utilisateurs lors de la réalisation du modèle :
Une partie de l’onglet « données » est fournie ci-dessous. Les utilisateurs doivent remplir les cellules d’entrée en utilisant les valeurs de développement, d’exploitation et d’évitement des pertes dues aux inondations pour l’option considérée. Les cellules clés de l’onglet « entrée » sont « nommées » pour faciliter le remplissage dynamique de l’onglet de données.
Figure 5-6 : Onglet « données » du modèle CanFlood BCA.
Une fois l’onglet « données » terminé, entrez un « taux d’actualisation » approprié qui doit être entré dans l’onglet « smry ». Les taux d’actualisation positifs sont couramment utilisés dans l’analyse financière pour refléter l’opinion selon laquelle les choses de valeur (par exemple, le capital) valent plus aujourd’hui qu’à l’avenir. Cela ne doit pas être confondu avec l’inflation. L’application de taux d’actualisation positifs est inappropriée lors de l’évaluation d’actifs de plus en plus rares, comme la fonction écosystémique et les espaces sauvages. Certains auteurs et lignes directrices proposent des taux d’actualisation variables (Smith et al. 2016). Des conseils sur la sélection d’un taux d’actualisation approprié sont fournis ailleurs (Farber 2016).
Après avoir rempli les onglets « données » et « smry », le classeur doit afficher les résultats résumés ci-dessous :
- PV avantages $
valeur actuelle des totaux des avantages
- PV coûts $
valeur actuelle des coûts totaux
- VAN $
valeur actuelle nette des coûts et avantages
- Ratio B/C
rapport des avantages PV sur les coûts PV
Finance du tracé
Cet outil génère un graphique de séries chronologiques financières des données sur les avantages et les coûts contenues dans la feuille de calcul BCA.
5.4. Outils supplémentaires
La section suivante décrit certains outils supplémentaires fournis dans la plateforme CanFlood qui prennent en charge la modélisation des risques d’inondation au Canada. Ceux-ci sont accessibles à partir du menu CanFlood (Plugins > CanFlood).
5.4.1. Cartographe de la fragilité des digues
Pour les modèles de risque qui intègrent la défaillance de la défense des digues, un ensemble de données contenant les probabilités conditionnelles de chaque actif réalisant la défaillance, appelé ensemble de données de probabilité d’exposition résolue (« exlikes »), est requis par les modules Risque (L1) et Risque (L2). Généralement, cet ensemble de données est généré à partir d’un ensemble de « polygones de défaillance » à l’aide de l’outil « Conditionnel P » dans le jeu d’outils de construction (Section 5.1.5_). Alors que certains projets peuvent avoir ces « polygones de défaillance » disponibles, souvent seuls les rasters d’événements et les informations sur les digues discutées dans la Section 4.5_ sont disponibles. Pour des cas comme celui-ci, le flux de travail résumé dans la Figure 5-7_ peut être utilisé, en commençant par l’outil « Dike Fragility Mapper » qui fournit une collection d’algorithmes pouvant être utilisés pour générer des polygones de rupture à partir d’informations typiques sur les digues.
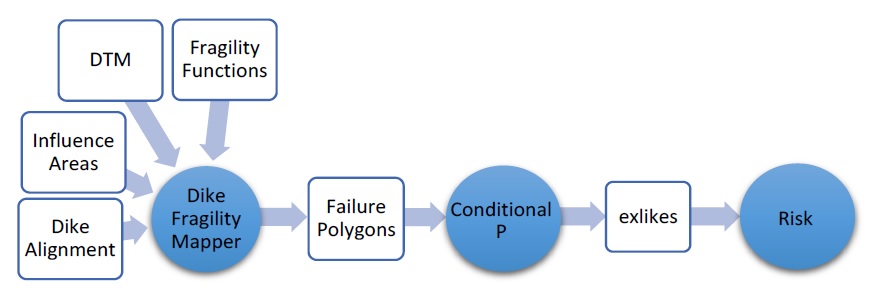
Figure 5-7 : Flux de travail typique des outils CanFlood, intégrant la fragilité des digues, où l’outil « Dike Fragility Mapper » est utilisé pour développer la couche de données des polygones de défaillance.
L’outil « Dike Fragility Mapper » est similaire à bien des égards au module Impacts (L2) appliqué aux actifs à géométrie linéaire, mais avec l’ajout d’un échantillonnage raster décalé spécial, une jonction intelligente des résultats aux polygones et des considérations de segmentation spécifiques à la digue une analyse. Cet outil est exécuté en trois étapes résumées ci-dessous. Pour plus d’informations sur l’application de cet outil, consultez le didacticiel 6a (Section6.11_).
Digue d’exposition
Le sous-outil d’exposition de digue détermine l’emplacement de la vulnérabilité la plus élevée sur chaque segment de digue, puis renvoie la valeur de franc-bord correspondante de chaque raster d’événements produisant l’ensemble de données d’exposition de segment de digue (« dexpo »). Ceci est accompli avec la séquence suivante:
Générer des transects à des intervalles spécifiés sur le côté spécifié de chaque segment de digue (lignes rouges sur la Figure 5-8_).
Échantillonner l’élévation de la crête de la digue à partir du raster MNT à la tête de chaque transect ;
Échantillonner chaque raster WSL d’événement sur chaque transect ;
Calculer les valeurs de franc-bord sur chaque transect comme la différence entre les valeurs WSL échantillonnées et les valeurs d’élévation de la crête ;
Calculez la valeur de franc-bord du segment en appliquant la statistique récapitulative aux valeurs de transect pertinentes (la valeur par défaut est la valeur minimale).
Figure 5-8 : Exemple de composants d’algorithme pour la routine d’exposition de l’outil Dike Fragility Mapper
Ce sous-outil fournit les sorties suivantes :
ensemble de données d’exposition du segment de digue (“dexpo”) : sortie freeboard .csv et entrée principale du sous-outil Dike Vulnerability ;
couche de digues traitées (facultatif) : il s’agit d’une version modifiée du fichier d’entrée d’origine, montrant les données “dexpo” sur la géométrie des digues d’origine.
couche de transects (facultatif) : ce sont les segments perpendiculaires de longueur et d’espacement spécifiés par l’utilisateur où l’élévation de la crête et l’échantillonnage WSL sont effectués respectivement en tête et en queue ;
points d’exposition du transect (facultatif) : chaque tête de transect avec toutes les valeurs calculées ;
couche de points de rupture (facultatif) : têtes de transect avec des valeurs de franc-bord négatives ;
traces de profil de segment de digue (facultatif) : trace de profil de segment de digue montrant les élévations de crête échantillonnées et le WSL (voir ci-dessous).
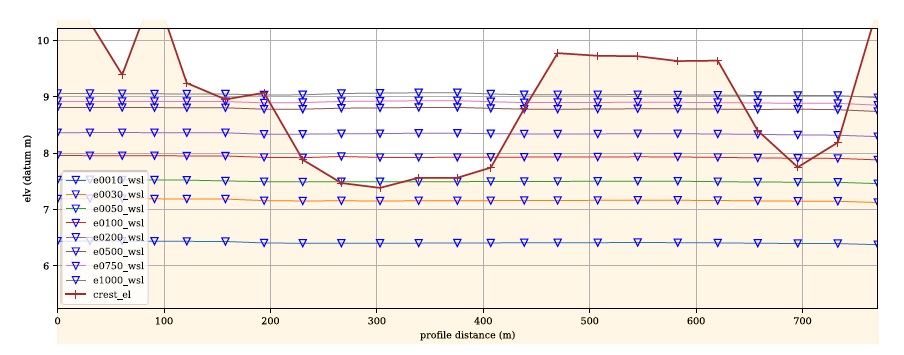
Vulnérabilité des digues
Le sous-outil « Dike Vulnerability » alimente l’entrée pertinente de l’ensemble de données d’exposition du segment de digue (« dexpo ») dans la courbe de fragilité associée à chaque segment de digue. Ce sous-outil génère un fichier csv de données tabulaires de probabilité de défaillance (« pfail »).
Les algorithmes suivants sont disponibles pour ajuster les probabilités de défaillance résultantes pour « l’effet de longueur » :
URS (2008) : normaliser toutes les probabilités de défaillance par l’ensemble des longueurs de segments.
Une sortie secondaire similaire est fournie pour ces valeurs ajustées en longueur.
Résultats de probabilité d’échec de la digue Rejoindre
Cet outil joint simplement les données de probabilité de défaillance tabulaires sélectionnées aux polygones d’influence de la digue fournis pour générer les « polygones de défaillance » requis par l’outil « P conditionnel » (Section 5.1.5_).
Remarques et considérations
Lors de l’application du Dike Fragility Mapper à votre projet, les éléments suivants doivent être pris en compte :
CanFlood n’effectue aucune analyse hydraulique, l’utilisateur doit fournir des polygones d’influence indiquant la zone sur laquelle les actifs devraient avoir leur probabilité de réaliser le raster de défaillance WSL correspondant. Compte tenu de cela, les polygones d’influence peuvent s’étendre en toute sécurité au-delà des étendues raster sans affecter le calcul des impacts de défaillance.
Les fonctions de fragilité doivent être développées et étiquetées sur chaque segment raster par un expert géotechnique qualifié à l’aide de données de terrain.
5.4.2. Ajouter des connexions
« Ajouter des connexions » de CanFlood |addConnectionsImage| L’outil ajoute un ensemble précompilé de ressources Web au profil QGIS d’un utilisateur pour un accès et une configuration faciles (c’est-à-dire en ajoutant des informations d’identification). L’ensemble des ressources Web ajoutées par cet outil sont configurées dans le fichier “canflood_parsWebConnections.ini” (dans le répertoire du plugin de l’utilisateur). `Appendice A <appendix_a_>`__ résume les connexions Web ajoutées par cet outil.
Le Guide de l’utilisateur QGIS explique comment gérer et accéder à ces connexions. Une fois les ressources ajoutées au profil d’un utilisateur, deux méthodes de base peuvent être utilisées pour ajouter les données au projet :
Panneau de navigation : il s’agit de la méthode la plus simple mais ne prend en charge aucun raffinement de la demande de données. Dans le panneau du navigateur, développez le type de fournisseur d’intérêt (par exemple, ArcGisFeatureServer) > développez la connexion d’intérêt > sélectionnez la couche d’intérêt > cliquez avec le bouton droit de la souris > Ajouter une couche au projet.
Data Source Manager : il s’agit de la méthode recommandée car elle offre une plus grande polyvalence lors de l’ajout à partir de connexions de données. Ouvrez le gestionnaire de source de données (Ctrl + L) > sélectionnez le type de fournisseur d’intérêt > sélectionnez le serveur d’intérêt > sélectionnez la couche d’intérêt > spécifiez les paramètres de demande supplémentaires > cliquez sur « Ajouter » pour charger la couche dans le projet.
De nombreux plugins et outils utilisés par QGIS (et CanFlood) ne prennent pas en charge de telles couches Web (en particulier les rasters), donc la conversion et le téléchargement peuvent être nécessaires.
5.4.3. Convertisseur RFDA
L’outil Rapid Flood Damage Assessment (RFDA) a été développé par la province de l’Alberta en 2014 en tant que plug-in QGIS 2. RFDA n’a inclus aucune analyse spatiale ni aucun calcul de risque. Les inventaires RFDA sont au format tableur Excel (.xls) indexés par emplacement de colonne (pas d’étiquettes). Les courbes sont étiquetées sur les actifs à l’aide d’une concaténation des colonnes 11 et 12. De nombreuses colonnes de l’inventaire sont ignorées dans RFDA. Voici les colonnes fonctionnelles :
0 : “id1”,
10 : « classe »,
11:”struct_type”,
13 : « zone »,
18 : “bsmt_f”,
19:”ff_height”,
20 : “on”,*
21 : “lat”,*
• 25 : « gel »
*non utilisé par RFDA, mais nécessaire pour l’analyse spatiale.
RFDA utilise un format hérité pour lire les fonctions d’endommagement basées sur des emplacements de colonne alternés. Un exemple est fourni ci-dessous :
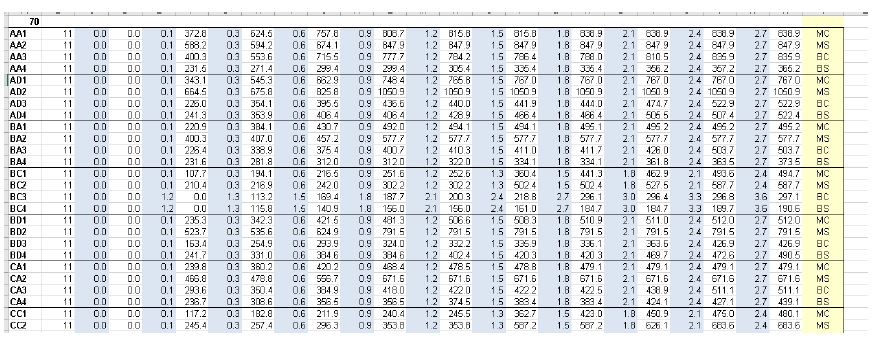
RFDA a été développé en parallèle avec un ensemble de fonctions de dommages 1D à partir d’enquêtes sur les bâtiments des structures à Edmonton et Calgary, AB en 2014. Les courbes pour le remplacement/la réparation des bâtiments et les dommages au contenu ont été développées séparément. Les courbes résidentielles du rez-de-chaussée et du sous-sol ont été élaborées séparément.
Au cours d’une exécution de modèle, RFDA applique un contenu et une courbe structurelle à chaque actif, et la paire de sous-sol correspondante à ceux avec “bsmt_f”=True.
Pour faciliter la conversion des inventaires RFDA au format CanFlood, deux outils sont fournis :
Convertisseur d’inventaire ; et
Convertisseur de courbe de dommages.
Conversion d’inventaire
La conversion d’inventaire RFDA nécessite une couche vectorielle de points comme entrée 3. Pour les inventaires résidentiels (ceux dont le struct_type ne commence pas par « S »), chaque actif se voit attribuer un f0_tag avec un suffixe « _M » pour le désigner comme une courbe d’étage principal (par exemple BD_M) basée sur la « classe » et le « type_struct » concaténés valeurs dans l’inventaire. En utilisant la valeur “bsmt_f”, le f1_tag est également affecté avec un suffixe “_B”. Ces suffixes correspondent au nom de courbe de l’outil DamageCurves (décrit ci-dessous). Le f1_elv est attribué à partir de : f0_elv – bsmt_ht.
Pour les inventaires commerciaux (ceux avec struct_type commençant par “S”), les champs f0_tag et f1_tag sont renseignés séparément avec les valeurs “struct_type” et “class”. Où “bsmt_f” = True, un troisième f2_tag=” nrpUgPark” est ajouté pour indiquer la présence d’un parking souterrain 4. Une fois converti, l’utilisateur peut démarrer le processus de construction du modèle CanFlood.
Convertisseur de courbes de dommages
Cet outil convertit les courbes au format RFDA en un ensemble de courbes CanFlood (une courbe par onglet). Les combinaisons suivantes de courbes RFDA sont construites :
Individuel (par exemple, contenu du rez-de-chaussée)
Étage combiné (par exemple, structure et contenu du rez-de-chaussée)
Type combiné (ex. sous-sol structurel et rez-de-chaussée)
Tous combinés
Cela permet à l’utilisateur de personnaliser quelles courbes sont appliquées et comment à chaque actif (avec la fonction « fonction de vulnérabilité composite » de CanFlood).
5.4.4. Ajouter des styles
Pour augmenter les styles de symboles emballés dans QGIS pour modifier l’affichage des caractéristiques des couches vectorielles, CanFlood inclut une petite bibliothèque de styles typiques pour les projets d’inondation SIG. Cette bibliothèque est un fichier .xml dans le répertoire des plugins et peut être ajoutée à votre gestionnaire de styles via le menu CanFlood comme indiqué ci-dessous :
Une fois exécutés, ces symboles doivent être disponibles pour styliser les couches vectorielles pertinentes via l’une des boîtes de dialogue de stylisation des couches QGIS. Par exemple, le groupe « CanFlood » est accessible via le volet « Style de calque » (F7) comme indiqué ci-dessous :
Le “Styling Manager” de QGIS |stylingManager| fournit une interface pour l’organisation et d’autres tâches liées aux styles.
6. Tutoriels
Cette section fournit quelques didacticiels pour permettre à un utilisateur de démarrer dans CanFlood. Il est suggéré de suivre les didacticiels de manière séquentielle, en se référant à la section 5 lorsque des informations plus détaillées sont souhaitées. Pour tous les didacticiels, le CRS du projet peut être défini en toute sécurité à partir de n’importe quelle couche de données, sauf indication contraire. Les didacticiels sont rédigés en supposant que les utilisateurs sont familiarisés avec QGIS et la modélisation des risques d’inondation basée sur les objets. Toutes les données du didacticiel se trouvent dans le dernier zip “tutorial_data” sur la page du projet.
6.1. Tutoriel 1a : Risque (L1)
Ce didacticiel guide l’utilisateur à travers l’application la plus simple de la modélisation des risques dans CanFlood, appelée analyse de niveau 1 (L1), où seule l’exposition binaire est calculée. Cette analyse « exposé vs non exposé » peut être utile pour l’analyse préliminaire lorsque les informations sont insuffisantes pour modéliser la vulnérabilité d’un objet plus complexe.
6.1.1. Charger des données dans le projet
Téléchargez les couches de données pour le didacticiel 1 :
haz_rast : rasters d’événements dangereux avec prédictions de valeurs WSL pour la zone d’étude pour quatre probabilités.
o haz_0050.tif
o haz_0100.tif
o haz_0200.tif
o haz_1000.tif
finv_tut1a.gpkg : inondation de la couche spatiale d’inventaire des actifs (“finv”).
Assurez-vous que le CRS de votre projet est défini sur “EPSG:3005” 5 et chargez les couches téléchargées dans un nouveau projet QGIS 6. Votre canevas de carte devrait ressembler à ceci :

Explorez les attributs de la couche d’inventaire des ressources d’inondation (“finv”) (F6). Vous devriez voir quelque chose comme ceci :
Les 4 champs sont :
fid : identifiant de fonction intégré (non utilisé) ;
xid : Index FieldName, identifiant unique de l’asset 7 ;
f0_scale : valeur pour mettre à l’échelle les résultats du calcul “f0” pour cet actif ;
f0_elv : hauteur (au-dessus de la référence du projet) à laquelle l’actif est vulnérable aux inondations.
Pour cet exemple, chaque entrée d’inventaire ou « actif » pourrait représenter une maison avec l’élévation du rez-de-chaussée entrée dans « f0_elv ». Toutes les eaux de crue au-dessus de cette altitude seront compilées en tant qu’impact pour cet actif. Pour l’analyse L1 de CanFlood, sur la base de la probabilité fournie par l’utilisateur de chaque événement, le « risque d’inondation » total pour chaque actif et pour la zone d’étude complète sera calculé.
6.1.2. Construire le modèle
Appuyez sur le bouton “Build” |buildimage| pour commencer à construire un modèle CanFlood.
Installer
Dans l’onglet « Configuration », configurez votre « session de génération » en créant ou en sélectionnant d’abord un répertoire de travail facile à localiser à l’aide du bouton « Parcourir ». CanFlood placera tous les fichiers de données assemblés avec l’ensemble d’outils « Build » dans ce répertoire. Assurez-vous que les « contrôles de construction » restants sont spécifiés comme indiqué ci-dessous.
Utilisez maintenant la partie inférieure de la boîte de dialogue pour spécifier les paramètres que CanFlood doit utiliser pour assembler votre nouveau fichier de contrôle, comme indiqué ci-dessous.
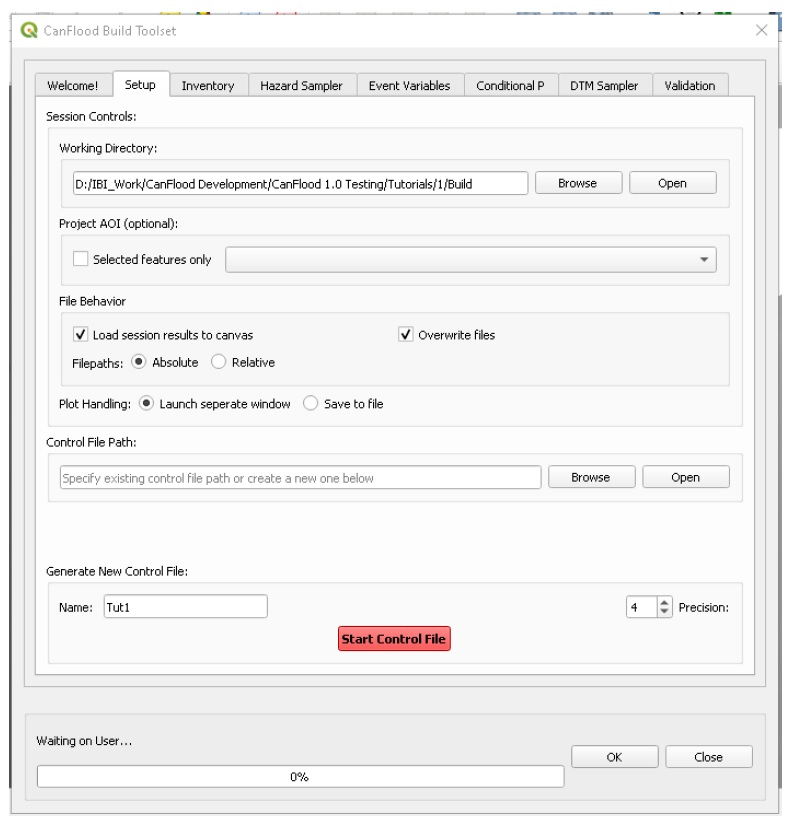
Une fois les paramètres correctement saisis, cliquez sur “Démarrer le fichier de contrôle” pour créer votre fichier de contrôle dans le répertoire de travail. Il devrait y avoir un message sur la barre d’outils QGIS indiquant que le processus s’est déroulé avec succès.
Si vous affichez l’onglet Messages du journal « CanFlood » (Affichage > Panneaux > Messages du journal), vous pouvez voir les messages du journal pour le processus que vous venez de terminer. Ça devrait ressembler a quelque chose comme ca:
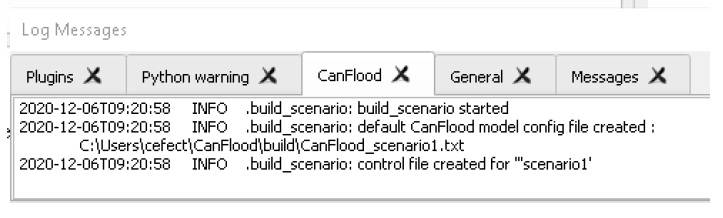
De retour dans l’onglet « Configuration » de CanFlood, à côté du chemin du fichier du répertoire de travail, cliquez sur « Ouvrir » pour ouvrir le répertoire de travail spécifié, vous devriez voir le fichier de contrôle « CanFlood_Tut1.txt » créé dans votre répertoire de travail. Ouvrez le fichier de contrôle. Il s’agit d’un modèle avec des paramètres vierges, par défaut et spécifiés. Au fur et à mesure que vous travaillez sur le reste de la section « Construire » de ce didacticiel, les paramètres vides seront remplis par les outils CanFlood. Remarquez le commentaire “#” vous indiquant comment et quand ce fichier de contrôle a été créé. Les lignes de commentaire « # » sont ignorées par le programme lors de la lecture à partir du fichier de contrôle et sont écrites par certains outils pour aider l’utilisateur à suivre les actions entreprises par CanFlood sur le fichier de contrôle.
Inventaire du magasin
Accédez à l’onglet « Inventaire ». Dans la section Compilateur d’inventaire, sélectionnez la couche d’inventaire (finv_tut1a) et assurez-vous que « type d’élévation » est défini sur « datum » pour refléter que les valeurs « f0_elv » de l’inventaire sont mesurées à partir des données du projet (plutôt que du sol). Sélectionnez maintenant la couche de vecteur d’inventaire et le “Index FieldName” approprié comme indiqué, puis cliquez sur “Store”.
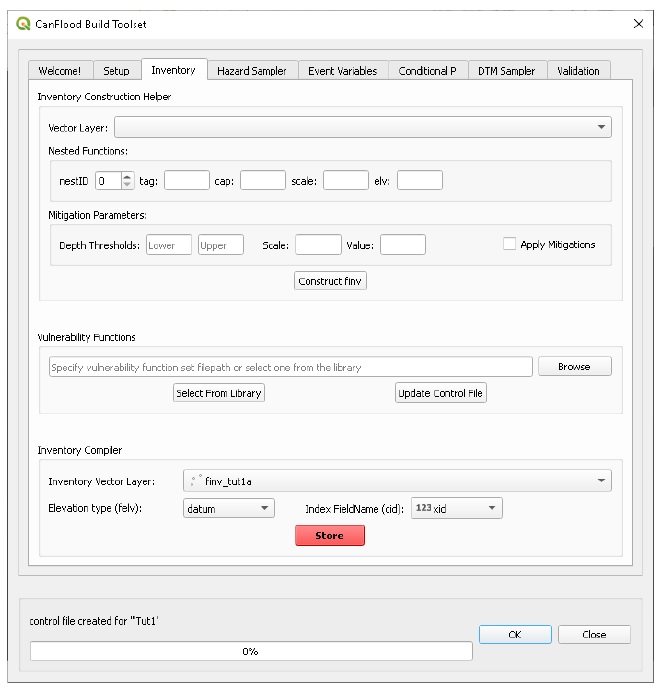
Vous devriez voir le fichier csv d’inventaire stocké dans le répertoire de travail. Il s’agit d’une version simplifiée de la couche d’inventaire avec les données spatiales supprimées. Ouvrez à nouveau le fichier de contrôle. Vous devriez remarquer que le paramètre d’inventaire des actifs (“finv”) a été renseigné avec le nom de fichier du csv nouvellement créé.
Échantillonneur de danger
Accédez à l’onglet « Échantillonneur de danger ». Vérifiez tous les rasters de danger dans la zone d’affichage comme indiqué 8, en laissant les paramètres restants vides ou inchangés :
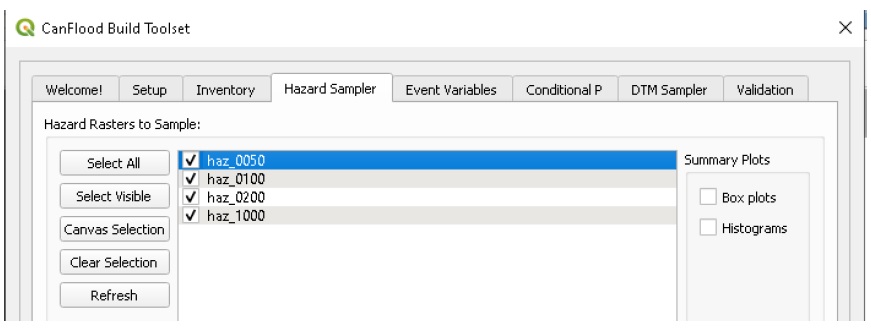
Cliquez sur « Sample Rasters » pour générer le jeu de données d’exposition (« expos »). Vous devriez voir un nouveau fichier csv dans le répertoire de travail et son chemin de fichier ajouté au fichier de contrôle sous « expos ». Il s’agit des WSL échantillonnés pour chaque actif de chaque raster d’événements dangereux.
Variables d’événement
Maintenant que les WSL ont été stockés, nous devons indiquer à CanFlood quelle est la probabilité de réaliser chacun de ces événements. Accédez à l’onglet « Variables d’événement ». Spécifiez les valeurs correctes pour la probabilité de chaque événement (à partir des noms d’événement) comme indiqué :
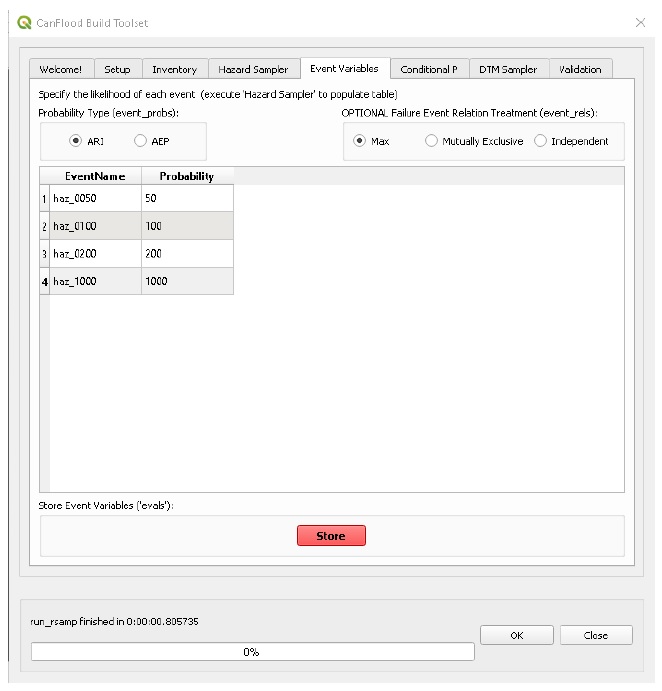
Appuyez sur “Store”. L’ensemble de données des probabilités d’événement (“evals”) doit avoir été créé et son chemin de fichier écrit dans le fichier de contrôle sous “evals”.
Validation
Accédez à l’onglet “Validation”, cochez “Risque (L1)”, puis cliquez sur “Valider”. Cela vérifiera toutes les entrées dans le fichier de contrôle et définira l’indicateur de validation « risk1 » sur « True » dans le fichier de contrôle. Sans cet indicateur, le modèle CanFlood échouera.
Le fichier de contrôle doit maintenant être entièrement construit pour une analyse L1 et les entrées nécessaires rassemblées. Le fichier de contrôle terminé devrait ressembler à ceci (mais avec vos répertoires) :
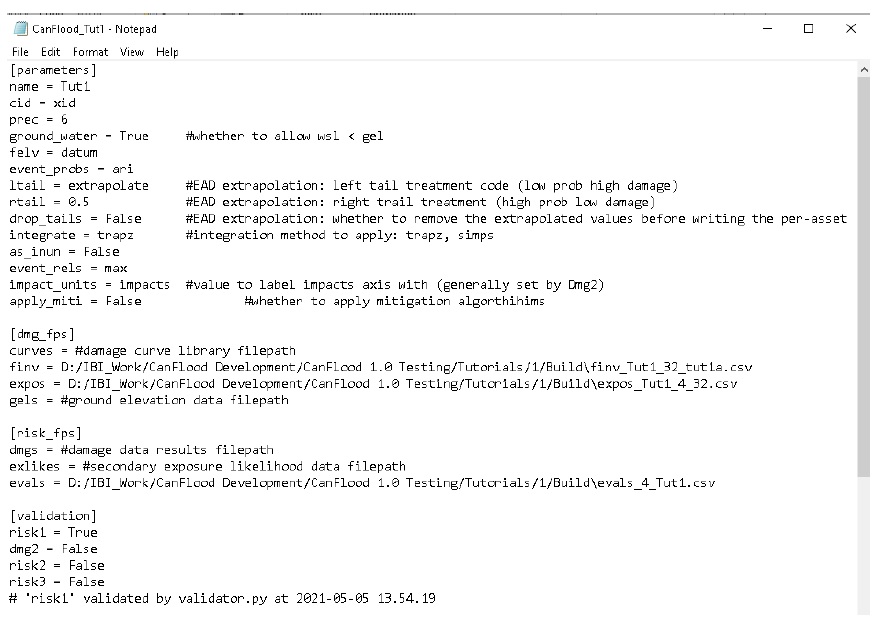
6.1.3. Exécuter le modèle
Cliquez sur le bouton “Modèle” |runimage| pour lancer la boîte de dialogue Jeu d’outils Modèle.
Installer
Dans l’onglet “Configuration”, sélectionnez un répertoire de travail 9 où tous vos résultats seront stockés. Sélectionnez également votre fichier de contrôle créé dans la section précédente si nécessaire.
Votre boîte de dialogue devrait ressembler à ceci 10 :
Exécuter
Accédez à l’onglet « Risque (L1) ». Cochez les deux premières cases comme indiqué ci-dessous et appuyez sur « Exécuter le risque1 » :
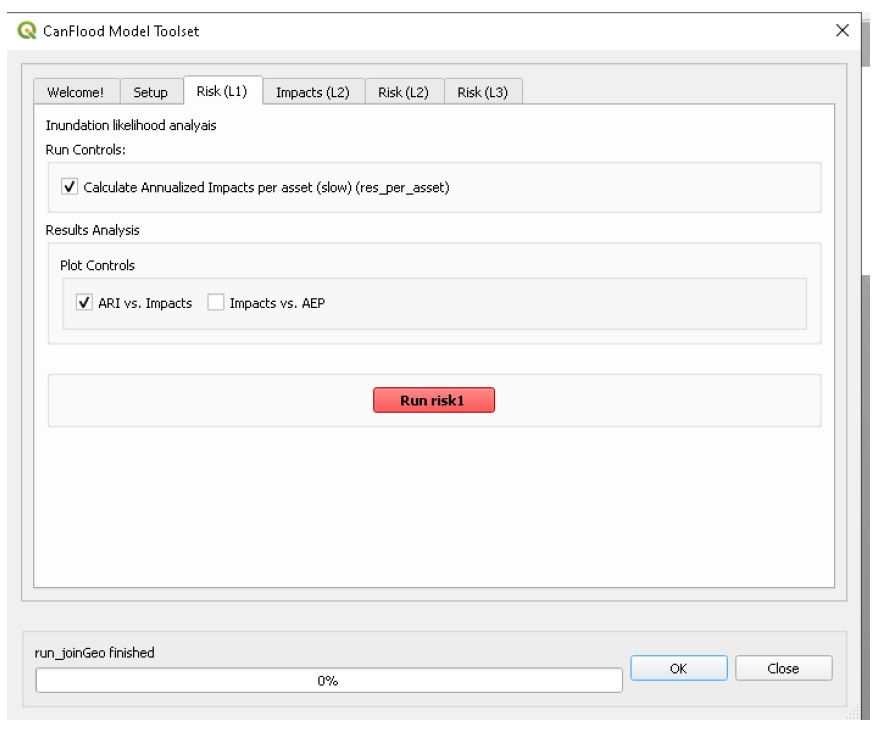
6.1.4. Voir les résultats
Accédez au répertoire de travail sélectionné. Vous devriez voir 3 fichiers créés :
risk1_run1_tut1a_passet.csv : valeur attendue de l’inondation par actif ;
risk1_run1_tut1a_ttl.csv : résultats totaux, valeur attendue de l’inondation totale par événement (et pour tous les événements) ;
tut1a.run1 Impact-ARI plot sur 6 events.svg : un plot des résultats totaux (voir ci-dessous).
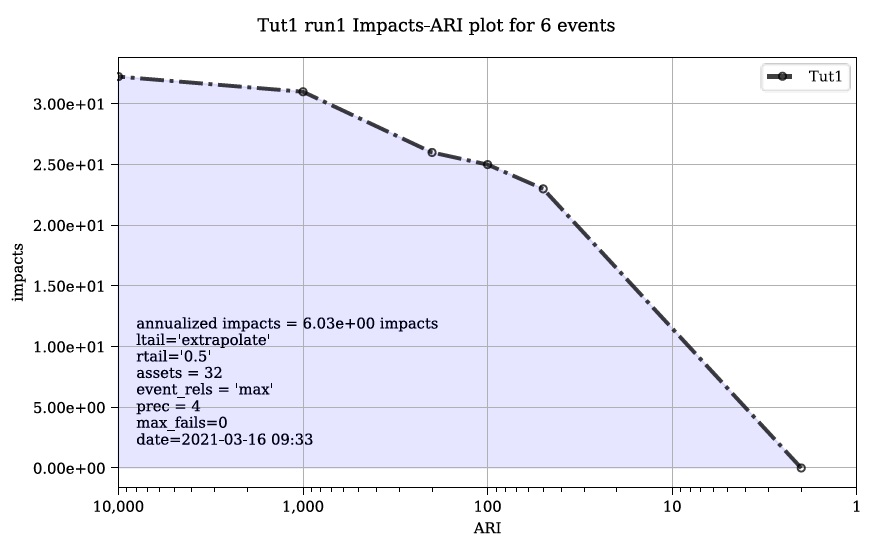
Ce sont les résultats non spatiaux qui sont directement générés par les routines de modèle de CanFlood. Pour faciliter une analyse et une visualisation plus détaillées, CanFlood est livré avec un troisième et dernier ensemble d’outils « Résultats ».
Rejoindre la géométrie
Ouvrez l’ensemble d’outils des résultats en cliquant sur le bouton “Résultats” |visualimage2| bouton. Les modèles CanFlood sont conçus pour fonctionner indépendamment de l’API spatiale QGIS. Par conséquent, si vous souhaitez afficher les résultats dans l’espace, des actions supplémentaires sont nécessaires pour rattacher les résultats du modèle tabulaire à la géométrie vectorielle de l’inventaire des actifs (“finv”). Pour ce faire, accédez à l’onglet « Rejoindre Geo », sélectionnez la couche d’inventaire des actifs (« finv »). Sélectionnez ensuite « r_passet » sous « paramètre de résultats à charger » pour remplir le champ ci-dessous avec un chemin de fichier vers votre fichier de résultats par actif 11. Enfin, sélectionnez l’option « Results Layer Style » et « Field re-label option » comme indiqué :
Cliquez sur “Rejoindre”. Un nouveau calque temporaire « joindre » doit avoir été chargé sur le canevas de la carte avec le style sélectionné appliqué. Déplacez ce calque vers le haut de votre panneau de calques et désactivez le calque « finv » d’origine pour voir le nouveau calque « join ». La couche « joindre » doit être une couche de points où la taille de chaque point est relative à l’ampleur de la valeur attendue de l’inondation (c’est-à-dire le nombre moyen d’inondations par an) similaire à ceci :
Ouvrez la table des attributs de la couche “joindre” (F6). Vous devriez quelque chose de similaire au tableau ci-dessous :
Notez que les six champs d’impact (encadrés en rouge ci-dessus) ont vu leurs noms convertis en « ari_probabilité » et les valeurs des champs fournissent les résultats d’exposition binaire (0=non exposé ; 1=exposé). Vous devrez enregistrer cette couche pour qu’elle soit disponible dans une autre session QGIS (volet Couches > Clic droit sur la couche > Enregistrer sous…). Félicitations pour votre première course CanFlood!
6.2. Tutoriel 2a : Risque (L2) avec des événements simples
Le didacticiel 2 montre l’utilisation du modèle « Risk (L2) » de CanFlood (Section5.2.3_). Cela émule une évaluation des risques plus détaillée où la vulnérabilité de chaque actif est connue et décrite en fonction de la profondeur de l’inondation (plutôt que de la simple présence d’inondation binaire comme dans le didacticiel 1). Ce didacticiel présente également un inventaire avec des hauteurs « relatives » et la fonctionnalité « fonction de vulnérabilité composite » de CanFlood où plusieurs fonctions sont appliquées au même actif.
6.2.1. Charger les données dans le projet
Téléchargez les données du tutoriel 2 depuis le dossier “tutorials2data” :
haz_rast : rasters d’événements dangereux avec prédictions de valeurs WSL pour la zone d’étude pour quatre probabilités.
o haz_0050.tif
o haz_0100.tif
o haz_0200.tif
o haz_1000.tif
finv_tut2.gpkg : inondation de la couche spatiale d’inventaire des actifs (“finv”)
dtm_tut2.tif : raster de modèle de terrain numérique avec prédictions d’élévation du sol
|ss| haz_frast : rasters d’événements d’échec du compagnon |se| (non utilisé dans le tutoriel 2a)
|ss| haz_fpoly : polygones d’événement d’échec du compagnon |se| (non utilisé dans le tutoriel 2a)
Chargez-les dans un projet QGIS, cela devrait ressembler à ceci :

6.2.2. Construire le modèle
Ouvrez le “Build” |buildimage| ensemble d’outils.
Configuration du scénario
Dans l’onglet « Configuration », configurez la session comme indiqué en utilisant vos propres chemins, puis cliquez sur « Démarrer le fichier de contrôle » :
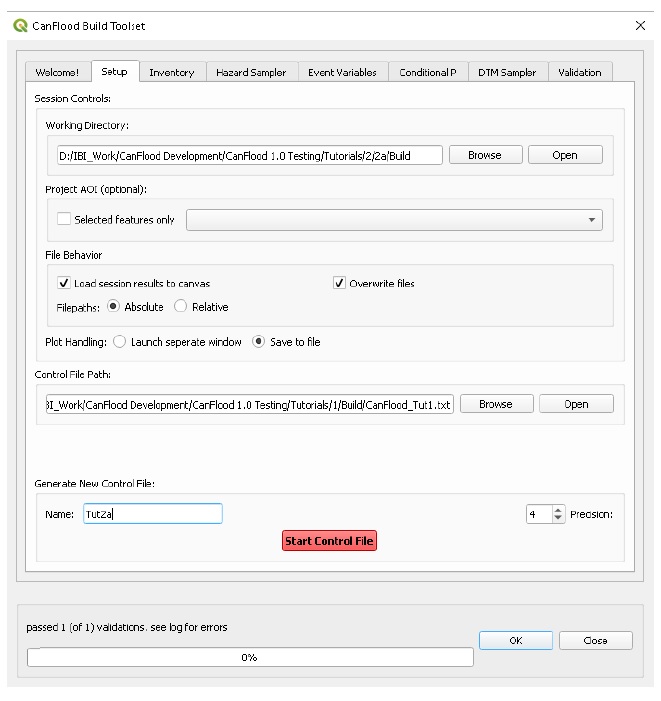
Sélectionnez l’ensemble de fonctions de vulnérabilité
Accédez à l’onglet « Inventaire » et cliquez sur « Sélectionner dans la bibliothèque » pour lancer l’interface graphique de sélection de bibliothèque illustrée ci-dessous. Sélectionnez la bibliothèque “IBI_2015” dans la fenêtre en haut à gauche puis “IBI2015_DamageCurves.xls” dans la fenêtre en bas à gauche, puis cliquez sur “Copy Set” pour copier cet ensemble de fonctions de vulnérabilité dans votre répertoire de travail. L’inventaire fourni dans ce tutoriel a été construit spécifiquement pour ces fonctions “IBI2015”. Généralement, les modélisateurs des risques d’inondation doivent développer ou fournir leurs propres fonctions de vulnérabilité.
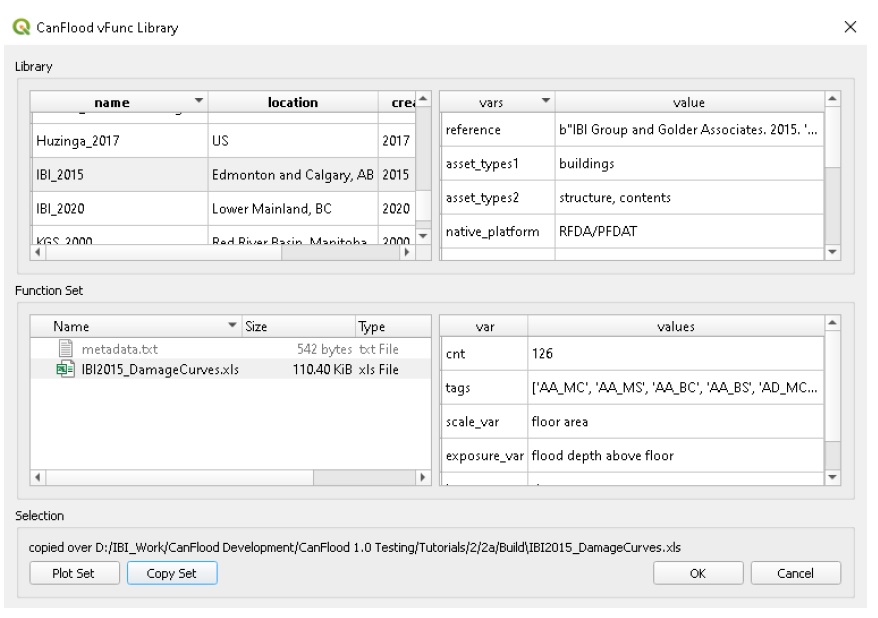
Fermez l’interface graphique “vFunc Selection” et vous devriez maintenant voir le nouveau chemin de fichier .xls entré sous “Vulnerability Functions”. Enfin, cliquez sur « Mettre à jour le fichier de contrôle » pour stocker une référence à cette fonction de vulnérabilité définie dans le fichier de contrôle.
Inventaire
Dans le même onglet « Inventaire », sélectionnez la couche vectorielle d’inventaire, le nom de champ d’index approprié et définissez le type d’élévation sur « sol » comme indiqué, puis cliquez sur « Stocker ».
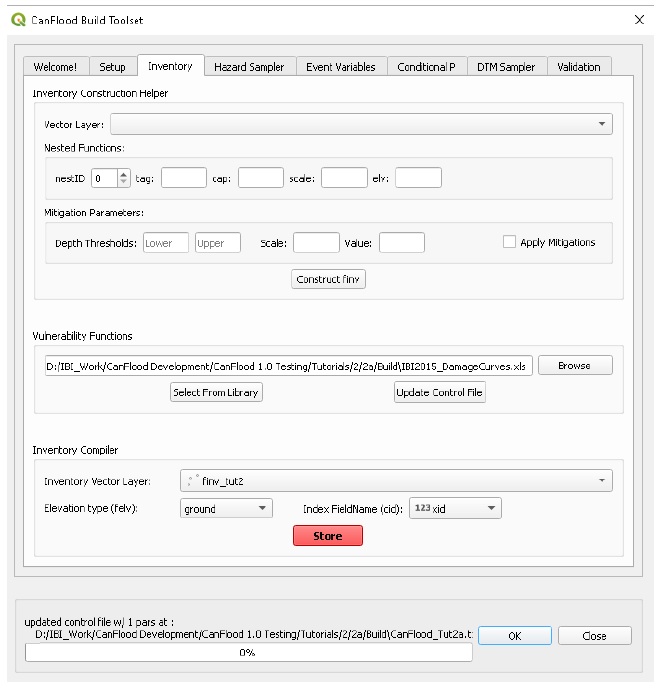
Vous devriez voir le csv d’inventaire maintenant stocké dans le répertoire de travail.
Échantillonneur de danger
Accédez à l’onglet « Hazard Sampler », assurez-vous que les quatre rasters de danger sont affichés dans la fenêtre et que tous les autres champs sont par défaut, puis cliquez sur « Sample Rasters ». Vous devriez voir le fichier de données “expos” créé dans le répertoire de travail.
Variables d’événement
Accédez à l’onglet « Variables d’événement », vous devriez maintenant voir les 4 événements dangereux de la tâche précédente remplir le tableau. Remplissez les valeurs de « Probabilité » comme indiqué (ignorez le paramètre « Relation d’événement d’échec » pour l’instant), puis cliquez sur « Stocker » pour générer l’ensemble de données des variables d’événement (« evals »).
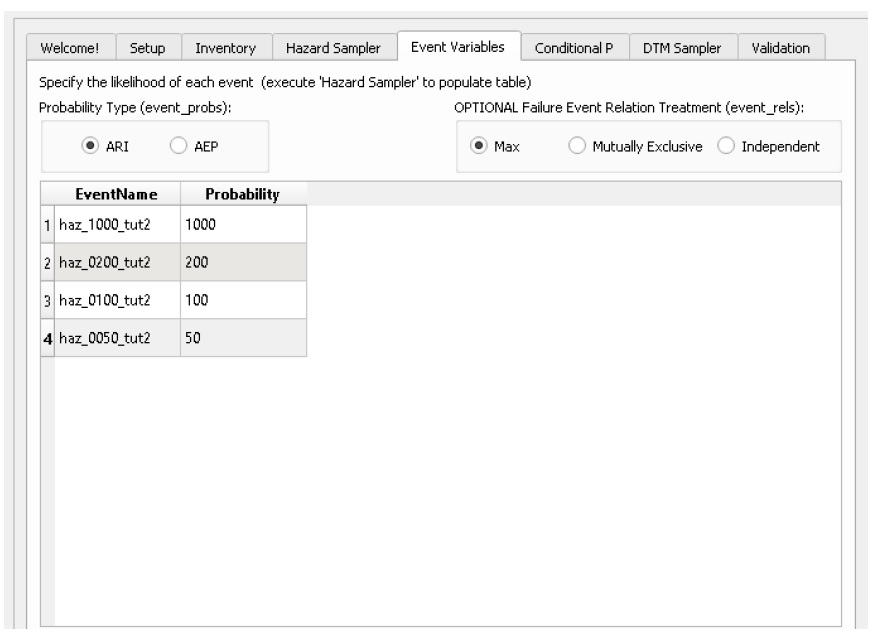
Échantillonneur DTM
Accédez à l’onglet “DTM Sampler”. Sélectionnez le raster “dtm_tut2” puis cliquez sur “Sample DTM” pour générer le jeu de données d’élévation du sol (“gels”) dans votre répertoire de travail et créez une référence dans le fichier de contrôle.
Validation
Accédez à l’onglet “Validation”, cochez les cases des deux modèles L2, puis cliquez sur “Valider”. Vous devriez obtenir un message de journal « passé 1 (sur 2) validations. voir journal”. Pour enquêter sur l’échec de la tentative de validation, ouvrez le panneau Messages du journal, il devrait ressembler à ceci :
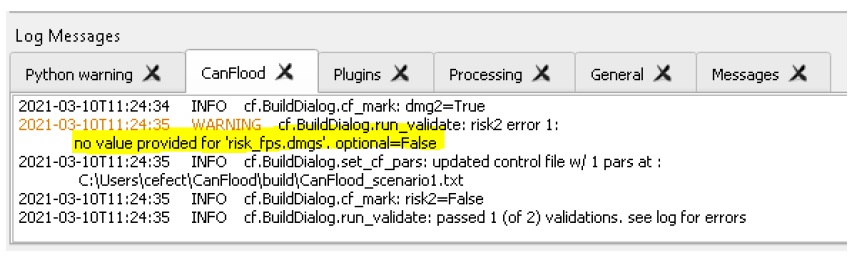
Cela montre que le modèle Risk (L2) ne contient pas le fichier de données « dmgs » et ne s’exécutera pas. Il s’agit d’un comportement attendu car CanFlood sépare le calcul de l’exposition (Impacts L2) du calcul du risque. Nous allons calculer ce fichier de données « dmgs » et valider pour le risque (L2) dans la section suivante. Vous êtes maintenant prêt à exécuter le modèle Impacts (L2) !
6.2.3. Exécuter le modèle
Ouvrez le “Modèle” |runimage| dialogue. Configurez l’onglet « Configuration » comme indiqué ci-dessous, en sélectionnant vos propres chemins et fichier de contrôle, et en vous assurant que le « Répertoire de sortie » est un sous-répertoire de votre précédent « Répertoire de travail » 12 :
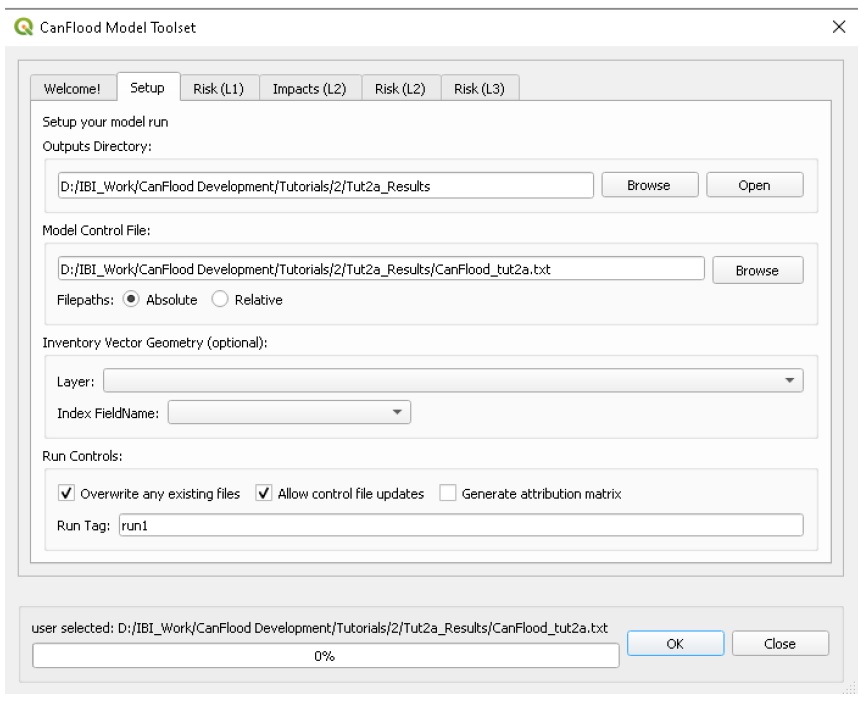
Impact (L2)
Accédez à l’onglet « Impacts (L2) ». Assurez-vous que la case « Exécuter le risque (L2) » n’est pas cochée (nous exécuterons le modèle de risque manuellement à l’étape suivante) mais que « Impacts du composant étendu de sortie » est cochée. Cliquez sur « Exécuter dmg2 ».
Cela devrait créer un fichier de données d’impacts (“dmgs”) dans votre répertoire de travail et remplir l’entrée correspondante sur le fichier de contrôle. Ouvrez ce csv. Ça devrait ressembler a quelque chose comme ca:
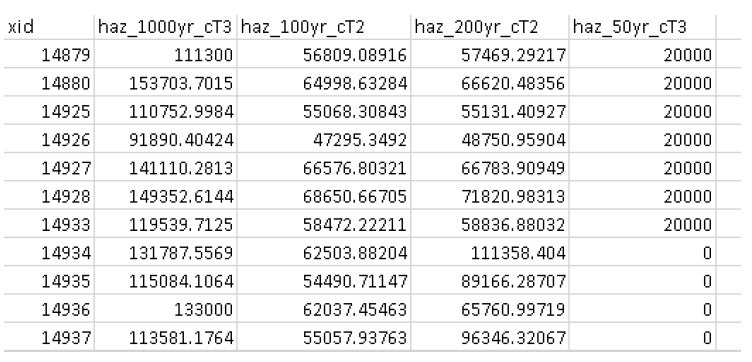
Il s’agit des impacts bruts par événement et par actif calculés avec chaque fonction de vulnérabilité, le WSL échantillonné et l’élévation DTM échantillonnée. Le deuxième résultat est les « impacts des composants étendus », un grand fichier d’arrière-plan de sortie facultatif utilisé par CanFlood qui contient la tabulation de chaque fonction imbriquée et les valeurs de mise à l’échelle et de plafond appliquées. Voir Section 5.2.2_ pour plus d’informations. Vous êtes maintenant prêt à calculer le risque d’inondation !
Risque (L2)
Accédez à l’onglet « Risque (L2) ». Cochez toutes les cases ci-dessous et cliquez sur « Exécuter le risque2 ».
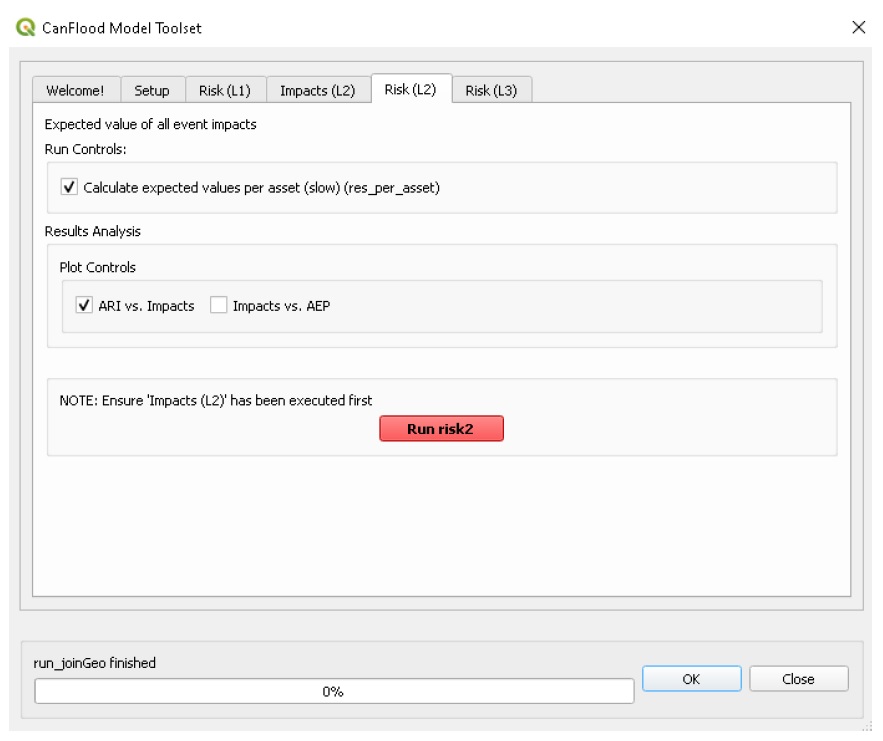
Un ensemble de fichiers de résultats aurait dû être généré (discuté ci-dessous). Pour une description complète du module Risque (L2), voir Section 5.2.3_.
6.2.4. Voir les résultats
Après avoir terminé l’exécution de Risk (L2), accédez à votre répertoire de travail. Il devrait maintenant contenir ces fichiers :
eventypes_run1_tut2a.csv : paramètres dérivés pour chaque raster ;
risk2_run1_tut2a_r2_passet.csv : valeur attendue par actif Résultats de risque étendus (L2) ;
risk2_run1_tut2a_ttl.csv : valeur totale attendue de tous les événements et actifs Résultats du risque (L2) ;
dmgs_tut2a_run1.csv : résultats des impacts par actif (L2) ;
dmgs_expnd_tut2a_run1.csv : résultats des impacts du composant étendu (L2) ;
run1 Impacts-ARI plot pour 6 events.svg : voir ci-dessous.
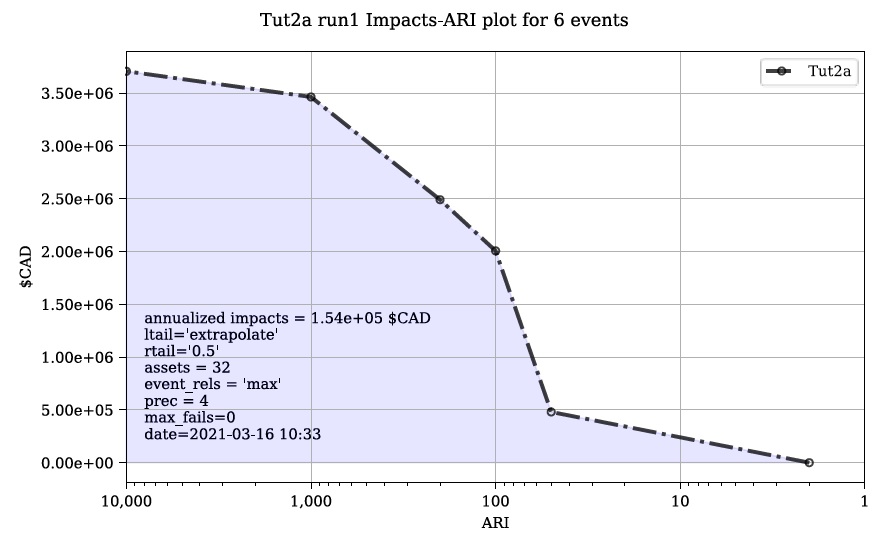
Figure 6-1 : Courbe de risque récapitulative des résultats du risque total (L2).
Tracés de risque
Alors que les modules de risque incluent certains tracés de courbe de risque de base (voir ci-dessus), CanFlood fournit une personnalisation de tracé supplémentaire sous l’outil « Risk Plot » dans l’ensemble d’outils « Résultats ». Ouvrez les “Résultats” |visualimage1| ensemble d’outils, configurez la session en sélectionnant un répertoire de travail, le fichier de contrôle, et en définissant « Gestion du tracé » sur « Enregistrer dans un fichier », comme indiqué :
Pour générer les tracés personnalisés, accédez à l’onglet « Risk Plot » et sélectionnez les deux types de tracés comme indiqué ci-dessous :
Pour personnaliser le tracé, ouvrez le fichier de contrôle et sous « [traçage] », modifiez les paramètres suivants :
couleur = rouge
impactfmt_str = ,.0f
Ces paramètres contrôlent la couleur du tracé et la mise en forme appliquée aux valeurs d’impact. Enregistrez les modifications, puis revenez à la fenêtre CanFlood et appuyez sur « Plot Total ». Vous devriez voir les deux tracés ci-dessous générés dans votre répertoire de travail.
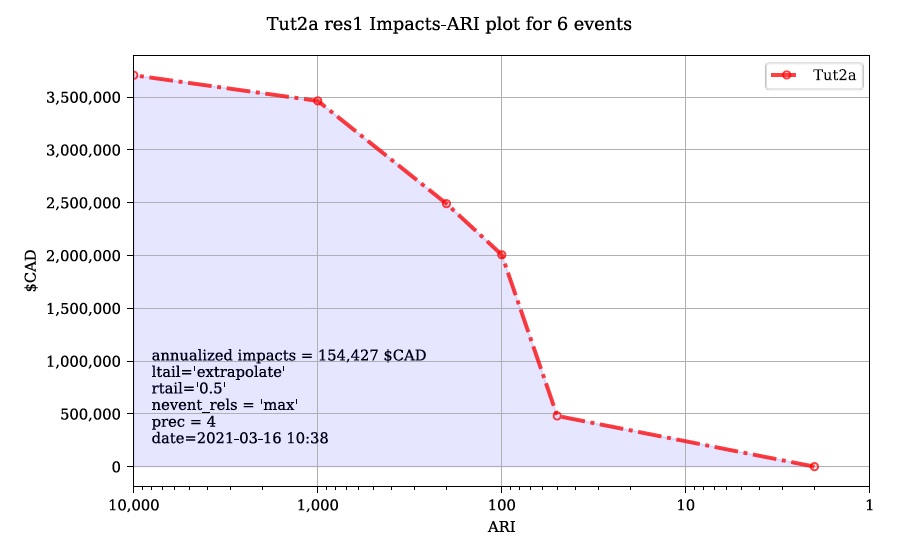
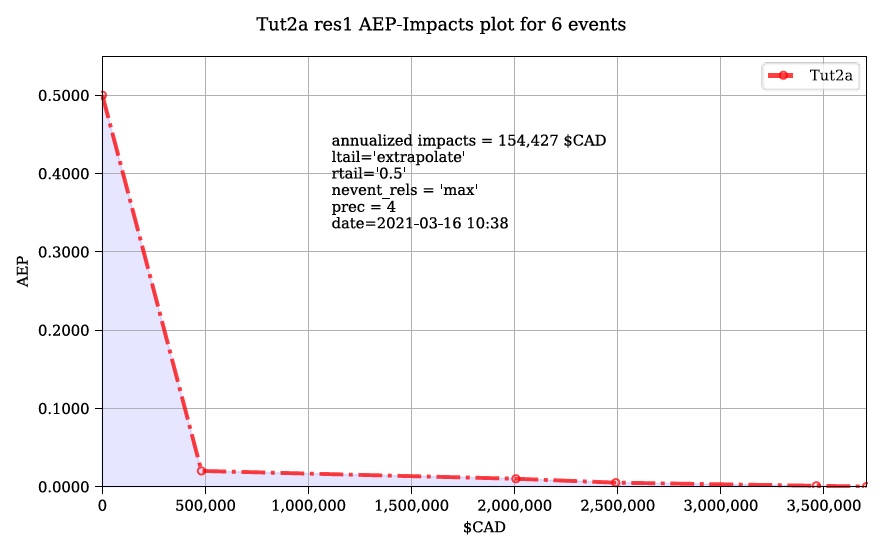
Ces graphiques sont les deux formats de courbe de risque standard pour les mêmes données de résultats totaux. Alternativement, changer « Gestion du tracé » en « Lancer une fenêtre séparée » dans l’onglet « Configuration » lancera une fenêtre de dialogue après le traçage qui fournit des outils intégrés pour personnaliser davantage le tracé.
6.3. Tutoriel 2b : Risque (L2) avec rupture de digue
Les utilisateurs doivent d’abord suivre les didacticiels 1 et 2a. Le didacticiel 2b utilise les mêmes données d’entrée que 2a mais étend l’analyse pour démontrer l’analyse des risques d’une simple défaillance de digue en incorporant un seul événement de défaillance compagnon dans le modèle. Cet événement d’échec associé est composé de deux couches :
haz_1000_fail_B_tut2 : « failure raster » indiquant le WSL qui serait réalisé si l’un des segments de digue échouait pendant l’événement ; et
haz_1000_fail_B_tut2 : couche de polygone de probabilité d’exposition conditionnelle avec des caractéristiques indiquant l’étendue et la probabilité de rupture de chaque segment de digue pendant l’inondation (“polygones de rupture”). Notez que cette couche contient deux entités qui se chevauchent par endroits, correspondant à des inondations potentielles provenant de deux sites de brèche dans le système de digue. Cette couche sera utilisée pour indiquer à CanFlood quand et comment échantillonner le raster d’échec.
Cette simplification en utilisant ces deux couches facilite la spécification de probabilités de défaillances multiples mais où toute défaillance (ou combinaison de défaillances) réaliserait le même WSL (les « conditions complexes » de la section 5.1.5_). Assurez-vous que ces couches sont chargées dans le même projet QGIS que celui utilisé pour le didacticiel 2a.
Pour mieux comprendre la couche « polygones de défaillance », appliquons le style « remplissage transparent transparent » de CanFlood. Commencez par charger ce modèle de style dans votre profil avec l’outil « Ajouter des styles » (Plugins > CanFlood > Ajouter des styles), puis appliquez-le à l’aide du panneau de style de calque (F7). Enfin, ajoutez une seule étiquette pour « p_fail » et déplacez le calque juste en dessous du calque de points d’inventaire des actifs (« finv ») dans le panneau des calques. Votre toile devrait ressembler à ce qui suit :
6.3.1. Construire le modèle
Suivez les étapes des didacticiels 2a « Créer le modèle », mais en incluant le « raster d’échec » (« haz_1000_fail_A_tut2 », probabilité=1000ARI) dans les étapes « Échantillonneur de risques » et « Variables d’événement ». À l’étape « Variables d’événement », assurez-vous que « Traitement de relation d’événement d’échec » est défini sur « Exclusif mutuel ».
Probabilités conditionnelles
Accédez à l’onglet « Conditionnel P » pour résoudre les polygones de défaillance qui se chevauchent dans le jeu de données de probabilités d’exposition résolues (« exlikes ») pour indiquer à CanFlood quelle probabilité doit être attribuée à chaque actif lors de la réalisation du raster de défaillance associé. Commencez par associer les polygones de défaillance avec le raster de défaillance, sélectionnez le « Nom du champ de probabilité », « Traitement de la relation d’événement » et « Plots récapitulatifs », comme indiqué, puis cliquez sur « Échantillon » :
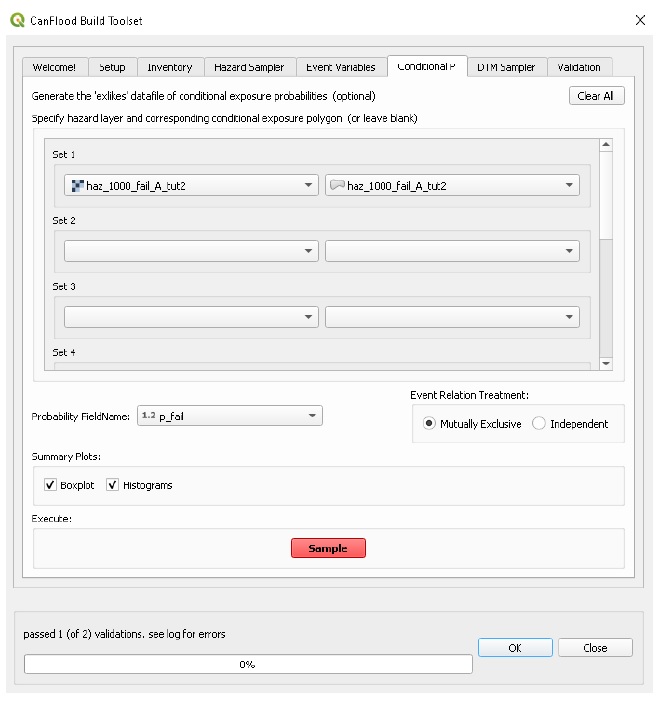
Un fichier de données de probabilités d’exposition résolues (« exlikes ») doit avoir été créé dans votre répertoire de travail avec des entrées comme celle-ci :
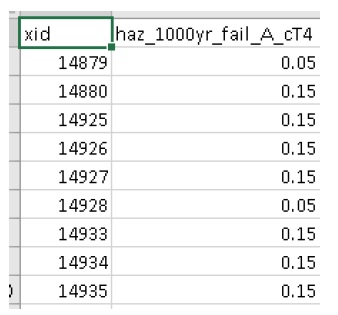
Deux graphiques récapitulatifs non spatiaux de ces données doivent également avoir été générés dans votre répertoire de travail, le plus utile pour ce modèle particulier étant l’histogramme :
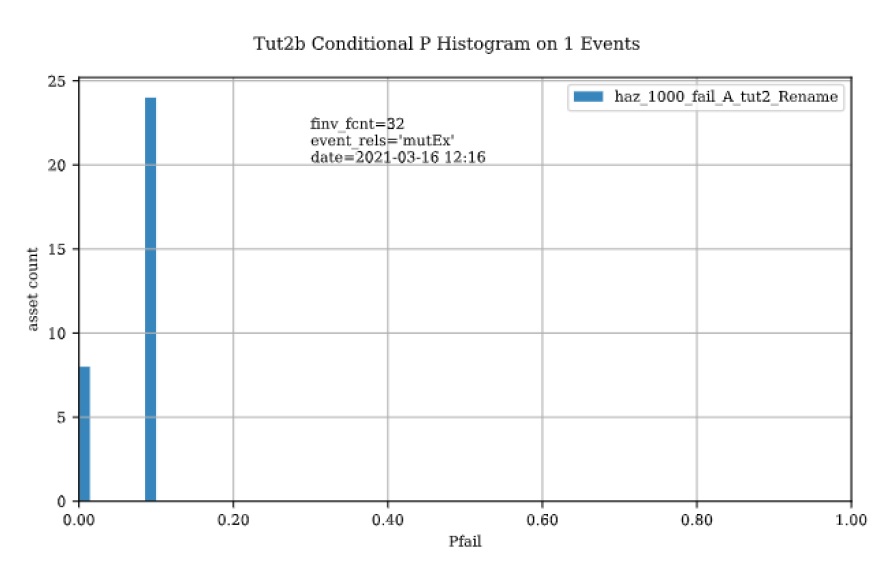
Ces valeurs sont les probabilités conditionnelles de chaque actif réalisant l’événement de défaillance compagnon de 1000 ans WSL. 13 Voir Section 5.2.3_ pour une description complète de cet outil. Terminez la construction du modèle en exécutant les outils « DTM Sampler » et « Validation ».
6.3.2. Exécuter le modèle
Ouvrez la boîte de dialogue “Modèle” |runimage| et configurez votre session de manière similaire au didacticiel 2a, mais assurez-vous que « Générer une matrice d’attribution » est coché sous « Exécuter les contrôles » (nous l’utiliserons pour créer des graphiques montrant les différents composants qui contribuent aux totaux de risque).
Impacts et risques
Accédez à l’onglet « Impacts (L2) », cochez la case « Exécuter le risque (L2) à la fin » pour exécuter les modèles d’exposition et de risque dans l’ordre à partir de votre fichier de contrôle. Accédez à l’onglet « Risque (L2) » et assurez-vous que « Calculer les valeurs attendues par actif » est coché. Revenez maintenant à l’onglet “Impacts (L2)” et cliquez sur “Exécuter dmg2”. Vous devriez voir les mêmes types de sorties que le didacticiel 2a, mais avec deux ensembles de données supplémentaires de « matrice d’attribution ».
6.3.3. Voir les résultats
Pour mieux comprendre l’influence de l’intégration de la défaillance des digues, cette section montrera comment générer un graphique montrant le risque total et la partie de ce risque total qui provient de l’absence de défaillance. Ouvrez l’ensemble d’outils « Résultats » et configurez votre session en sélectionnant un répertoire de travail et le même fichier de contrôle utilisé ci-dessus. Accédez maintenant à l’onglet « Risk Plot », assurez-vous que les deux contrôles de tracé sont cochés, puis cliquez sur « Plot Fail Split ». Cela devrait générer deux formulations de diagramme de risque, y compris la figure ci-dessous :
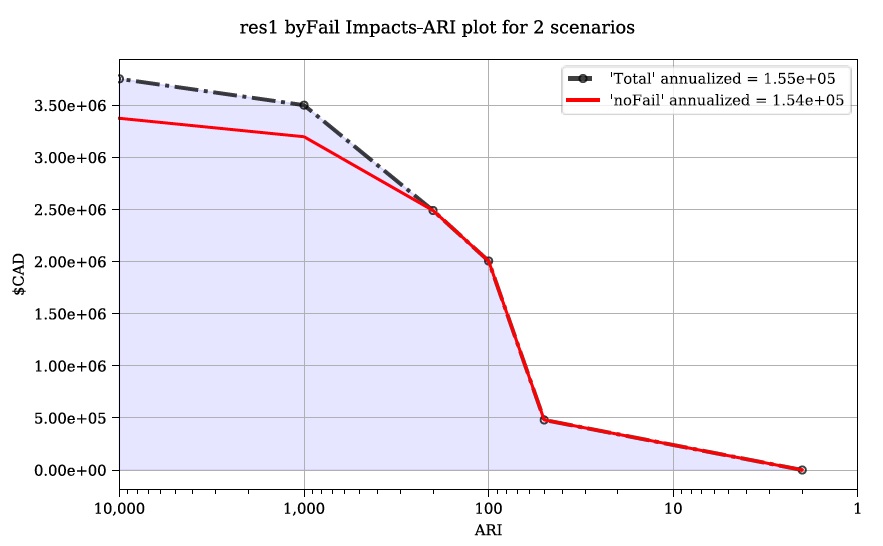
Dans ce graphique, la ligne rouge représente la contribution au risque sans les événements d’échec associés, qui devraient être presque identiques aux résultats du didacticiel 2a, et une deuxième ligne montrant les résultats totaux. 14 La zone entre ces deux lignes illustre la contribution au risque de l’intégration de la rupture de digue dans le modèle.
**************************************************** *************** 6.4. Tutoriel 2c : Risque (L2) avec défaillance complexe **************************************************** ***************
Il est recommandé aux utilisateurs de terminer d’abord le didacticiel 2b. Le didacticiel 2c utilise les mêmes données d’entrée que 2b mais étend l’analyse pour démontrer l’incorporation d’une défaillance de digue plus complexe avec deux événements de défaillance associés dans le modèle.
Dans le même projet QGIS que celui utilisé pour le didacticiel 2a, assurez-vous que les éléments suivants sont également ajoutés au projet :
haz_1000_fail_B_tut2.gpkg : polygone de défaillance “B” ;
haz_1000_fail_B_tut2.tif : raster d’échec “B”.
Ces couches représentent un événement de défaillance compagnon supplémentaire « B » pour l’événement de 1000 ans où le WSL de défaillance et les probabilités sont différents mais complémentaires de ceux de l’événement de défaillance compagnon « A » du didacticiel 2b. Ceux-ci pourraient être les résultats de deux scénarios de violation modélisés.
6.4.1. Construire le modèle
Suivez les étapes des didacticiels 2b « Créer le modèle », mais en incluant l’événement d’échec complémentaire « B » dans les étapes « Échantillonneur de risques », « Variables d’événement » et « Conditionnel P ». Pour les deux derniers, assurez-vous que les deux traitements de relation d’événement sont définis sur « Mutuellement exclusif ». L’examen de la boîte à moustaches « P conditionnelle » montre la différence entre les probabilités d’échec spécifiées par les deux événements d’échec associés :
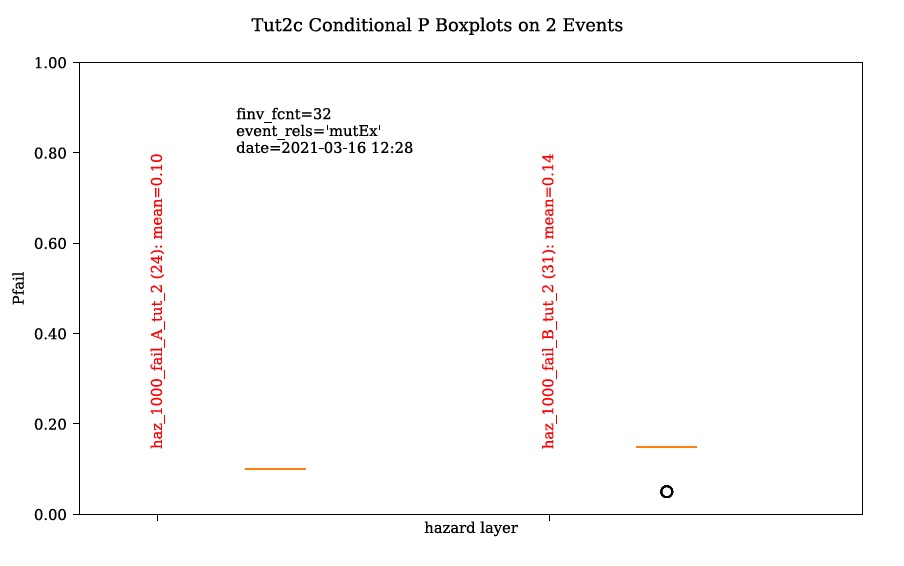
Terminez la construction du modèle en exécutant les outils « DTM Sampler » et « Validation ».
6.4.2. Exécuter le modèle
Ouvrez la boîte de dialogue “Modèle” |runimage| et suivez les étapes du didacticiel 2b pour configurer cette exécution de modèle.
Impacts et risques
Exécutez les modèles « Impacts (L2) » et « Risque (L2) » similaires au didacticiel 2b, mais assurez-vous que « Générer la matrice d’attribution » est désélectionné.
Pour explorer l’influence du paramètre “event_rels”, ouvrez le fichier de contrôle, changez le paramètre “event_rels” en “max”, changez le paramètre “name” en quelque chose d’unique (par exemple, “tut2c_max”), puis enregistrez le fichier avec un nom différent. Dans l’onglet “Configuration”, pointez sur ce fichier de contrôle modifié, un nouveau répertoire de sorties, et exécutez à nouveau les deux modèles comme décrit ci-dessus 15.
6.4.3. Voir les résultats
Après avoir exécuté le modèle “Risk (L2)” pour les fichiers de contrôle “event_rels=mutEx” et “event_rels=max”, deux collections similaires de fichiers de sortie doivent avoir été générées dans les deux répertoires de sortie distincts spécifiés lors de la configuration du modèle. Pour visualiser la différence entre ces deux configurations de modèle, ouvrez l’ensemble d’outils “Résultats” et sélectionnez un répertoire de travail et le fichier de contrôle d’origine “event_rels=mutEx” comme “fichier de contrôle principal” dans l’onglet “Configuration” [16 ]_. Avant de générer les fichiers de comparaison, configurez le style de tracé en ouvrant le même fichier de contrôle principal et en modifiant les paramètres “[traçage]” suivants :
“couleur = rouge”
“style de ligne = solide”
“impactfmt_str = ,.0f”
Pour générer un graphique de comparaison de ces deux scénarios, accédez à l’onglet « Comparer/Combiner », sélectionnez le « Fichier de contrôle » pour les deux configurations de modèle générées à l’étape précédente, assurez-vous que « Fichiers de contrôle » est coché sous « Contrôles de comparaison », comme indiqué ci-dessous:
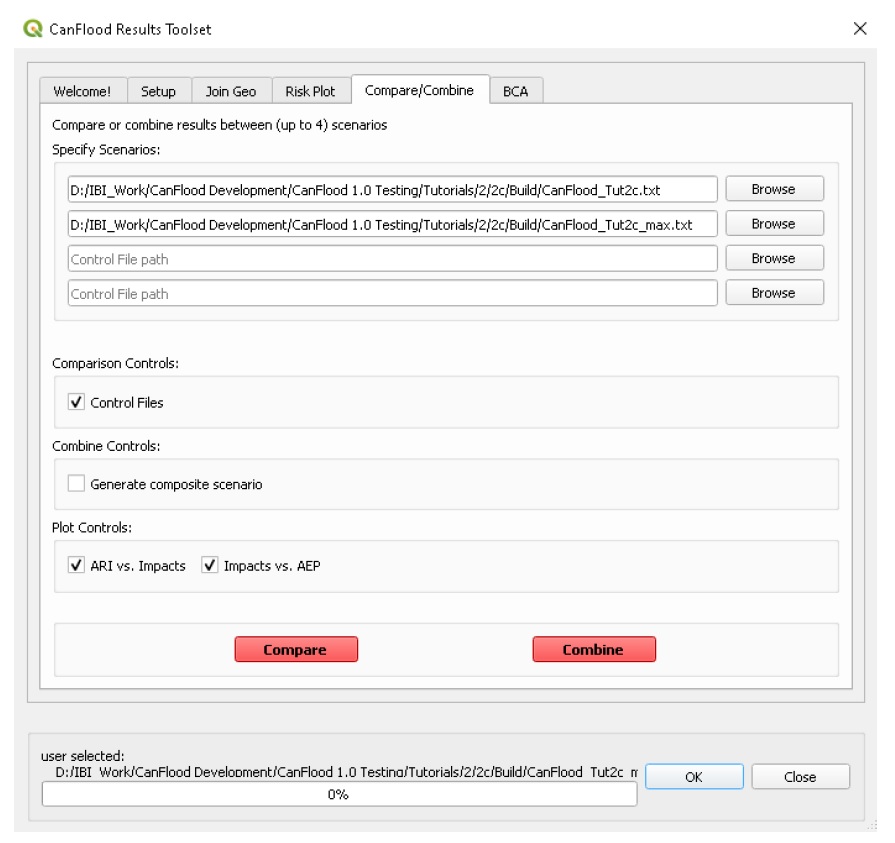
Cliquez sur « Comparer » pour effectuer la comparaison. Vous devriez voir deux fichiers générés dans votre répertoire de travail :
Graphique de comparaison montrant les deux courbes de risque sur le même axe ; et
Feuille de calcul de comparaison de fichiers de contrôle.
La feuille de calcul de comparaison des fichiers de contrôle est présentée ci-dessous et constitue un moyen simple d’identifier rapidement les distinctions entre les scénarios de modèle.
Sur le graphique de comparaison (illustré ci-dessous), notez que la différence entre les courbes de risque et les valeurs annualisées est négligeable, indiquant que le traitement des relations événementielles n’est pas très significatif pour ce modèle.
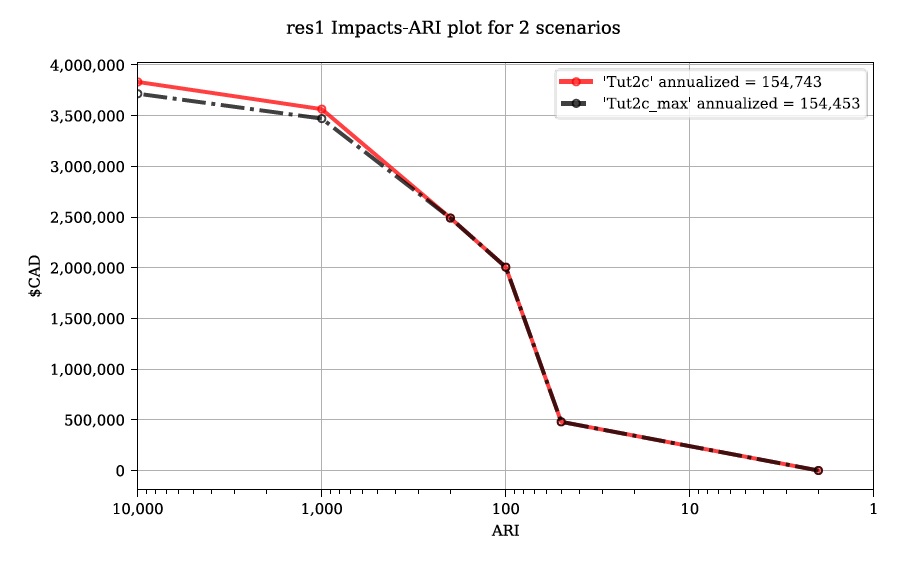
La réexécution de l’outil de comparaison sur les quatre fichiers de contrôle du didacticiel 2 construits jusqu’à présent donne les résultats suivants :
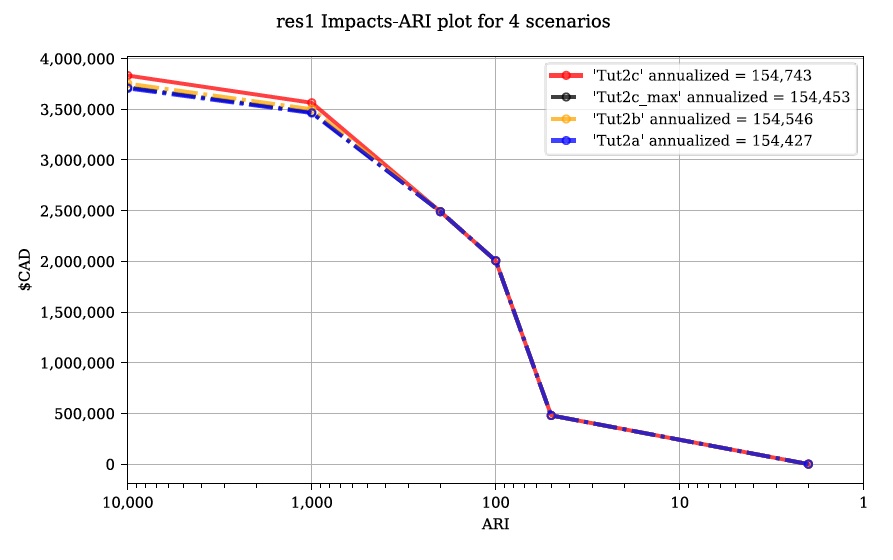
6.5. Tutoriel 2d : Risque (L2) avec atténuation
Il est recommandé aux utilisateurs de terminer d’abord le didacticiel 2a avant de continuer. Le didacticiel 2d utilise les mêmes données d’entrée que 2a mais étend l’analyse pour démontrer l’incorporation de mesures d’atténuation au niveau de l’objet (ou de la propriété) (PLPM) dans le modèle. Cela peut être utile pour améliorer la précision d’un modèle où deux actifs sont fonctionnellement similaires, utilisant la même fonction de vulnérabilité, mais où l’on dispose d’un mécanisme pour réduire l’exposition de l’actif (par exemple, un clapet anti-retour). De même, cette fonctionnalité peut être utilisée pour étudier les avantages de l’introduction des PLPM avec une analyse comparative.
6.5.1. Construire le modèle
Suivez les étapes des didacticiels 2a « Créer le modèle », à l’exception de l’étape « Inventaire », que nous modifierons pour appliquer quatre nouveaux champs à la couche vectorielle d’inventaire (« finv ») en configurant l’onglet « Inventaire » comme illustré ci-dessous avant de cliquer sur “Construire finv” :
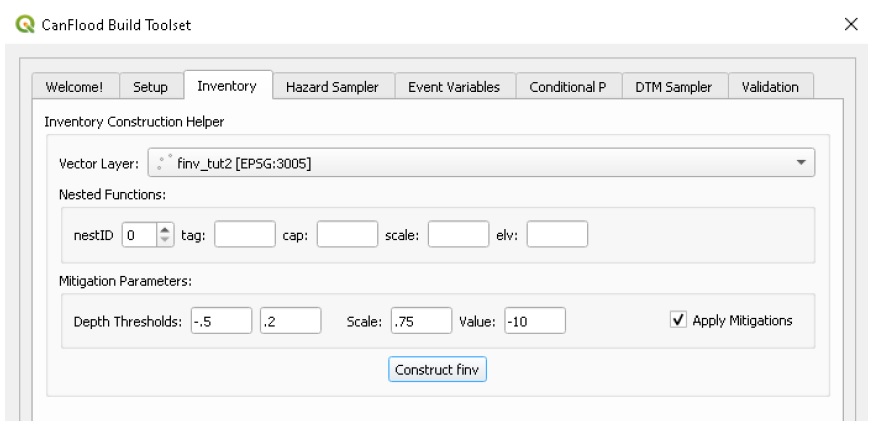
Cela devrait créer une nouvelle couche avec un préfixe « finv » dans votre canevas de carte. L’exploration de la table attributaire de cette couche (F6) devrait montrer les quatre nouveaux champs qui ont été créés et remplis avec les valeurs spécifiées. Ceux-ci sont utilisés par le module “Impacts (L2)” pour modifier l’exposition transmise à chaque fonction de vulnérabilité des objets et sont décrits dans la Section 5.2.2_. Terminez la construction de l’inventaire en vous assurant que « Appliquer les mesures d’atténuation » est coché, que la nouvelle couche de vecteur d’inventaire est sélectionnée et que le reste de l’onglet est configuré comme indiqué ci-dessous (identique au didacticiel 2a). Cliquez sur “Store”.
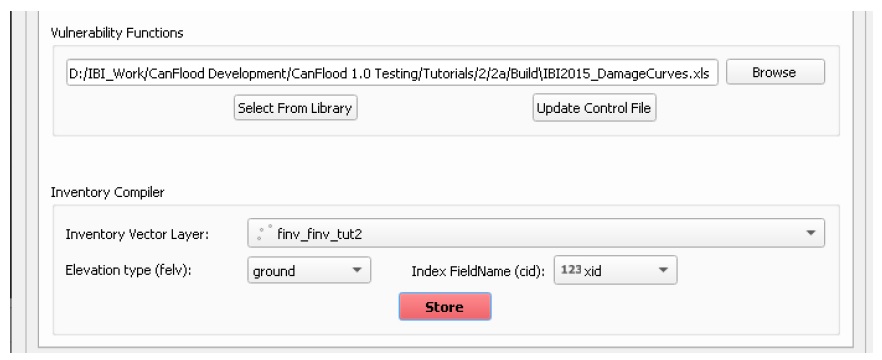
Effectuez les étapes « Échantillonneur de danger », « Variables d’événement », « Échantillonneur DTM » et « Validation » comme décrit dans le didacticiel 2a.
6.5.2. Exécuter le modèle
Ouvrez la boîte de dialogue “Modèle” |runimage| et configurez votre session comme dans le didacticiel 2a.
Impacts et risques
Accédez à l’onglet « Impacts (L2) » et assurez-vous que TOUS les « contrôles d’exécution » sont cochés, puis cliquez sur « Exécuter dmg2 ». Vous devriez voir les mêmes types de sorties que le didacticiel 2a, mais avec quelques sorties supplémentaires qui nous aideront à comprendre l’influence des paramètres d’atténuation, y compris la boîte à moustaches ci-dessous :
Cela affiche des résumés de données pour les quatre rasters d’événements, les valeurs d’impact total (en texte rouge) et certaines informations clés sur le modèle.
Pour comprendre l’effet des paramètres d’atténuation, ouvrez le fichier de contrôle, modifiez le paramètre “apply_miti” en “False”, modifiez le paramètre “name” en “tut2d_noMiti”, “color” en “red” et enregistrez-le sous un autre Nom. Dans l’onglet “Configuration”, pointez sur ce nouveau fichier de contrôle et remplacez le “Run Tag” par “noMiti”. Revenez maintenant à l’onglet “Impacts (L2)” et cliquez à nouveau sur “Exécuter dmg2”. Vous devriez voir un autre boxplot généré dans votre répertoire de travail :
Notez que les événements plus petits (50 ans et 100 ans) ont changé de manière significative, tandis que les événements plus importants le sont moins. Cela est logique étant donné que nous avons dit à CanFlood que les mesures d’atténuation seraient dépassées à des profondeurs supérieures à 0,2 m (via le paramètre de seuil de profondeur supérieur). Nous pouvons étudier plus en détail le comportement de ce modèle en ouvrant l’une des sorties 17 des « profondeurs_ », qui devraient ressembler à ce qui suit (les valeurs inférieures au seuil supérieur sont surlignées en rouge pour plus de clarté) :
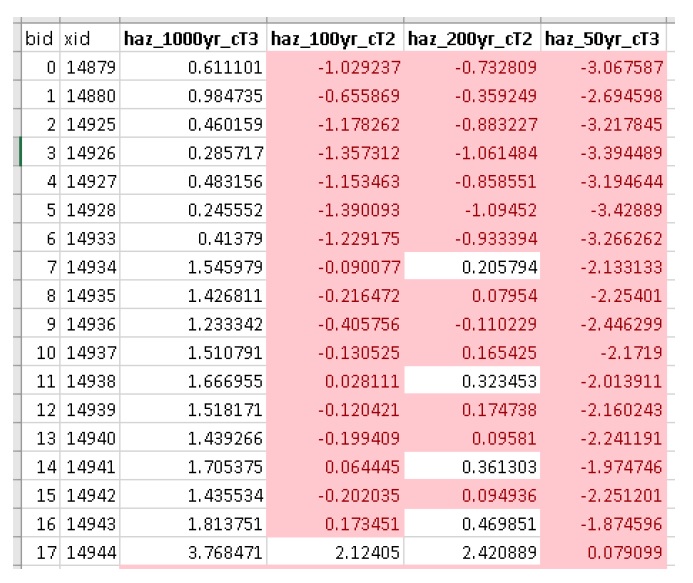
De même, l’onglet “_smry” de la feuille de calcul “dmg2_smry” pour l’exécution d’atténuation montre la variation des valeurs d’impact total (par événement) calculée à chaque étape du module “Impacts (L2)” (barres et flèches ajoutées pour plus de clarté) :
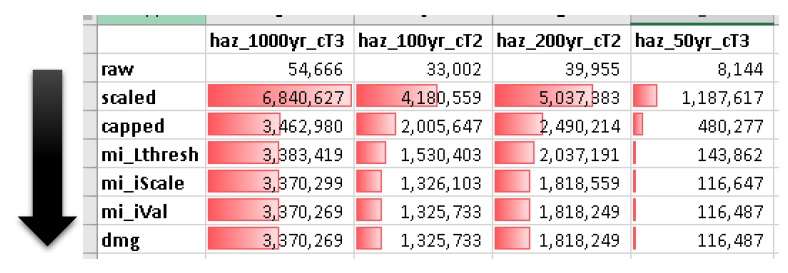
Cela montre les impacts totaux obtenus par les courbes brutes, puis l’algorithme de « mise à l’échelle » (« fX_scale »), l’algorithme « de plafonnement » (« fX_cap »), suivi de l’algorithme qui a appliqué le seuil inférieur (« mi_Lthresh »), l’atténuation mise à l’échelle (“mi_iScale”), l’ajout de valeur d’atténuation (“mi_iVal”) et le résultat final (identique à la ligne précédente). Cette progression montre que l’algorithme de « plafonnement » a eu une grande influence sur les résultats et que l’ajout de valeur d’atténuation (« mi_iVal ») a eu une influence négligeable.
6.5.3. Voir les résultats
L’outil « Comparer » des résultats peut être utilisé pour montrer l’influence sur la courbe de risque et le risque total :
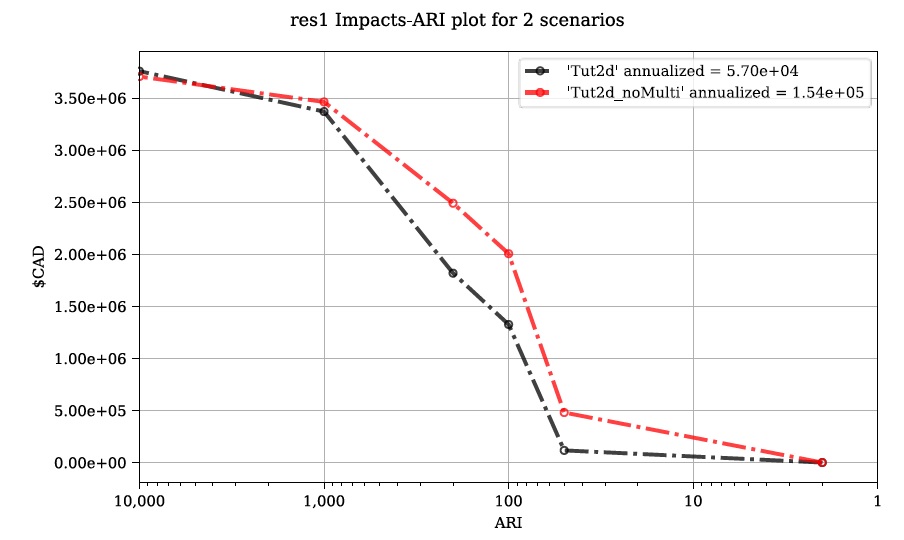
6.6. Tutoriel 2e : Analyse avantages-coûts
Ce didacticiel présente les outils d’analyse avantages-coûts (BCA) de CanFlood pour prendre en charge l’analyse avantages-coûts de base pour les interventions contre les risques d’inondation comme les mesures d’atténuation envisagées dans le didacticiel précédent. Avant de poursuivre ce didacticiel, les utilisateurs doivent avoir terminé et disposer des données de résultats pour le didacticiel 2a 18 et 2d :
CanFlood_tut2a.txt : fichier de contrôle du didacticiel 2a avec fichier et chemin d’accès des résultats totaux valides (“r_ttl”);
CanFlood_tut2d.txt : fichier de contrôle du didacticiel 2d avec le chemin d’accès du fichier des résultats totaux valides (“r_ttl”).
Commencez par ouvrir la boîte à outils “Résultats” puis accédez à l’onglet “Configuration” pour le configurer à l’aide du fichier de contrôle du didacticiel 2d. Nous allons maintenant générer un tracé de test pour nous assurer que nos fichiers de contrôle sont valides. Assurez-vous que le paramètre “impactfmt_str” est défini sur “,.0f” (pas d’apostrophe) dans le fichier de contrôle Tutorial 2d. Passez maintenant à l’onglet « Comparer/Combiner », entrez les deux fichiers de contrôle, cochez l’un des « Contrôles de tracé », puis cliquez sur « Comparer ». Un tracé identique à celui généré à la fin du Tutoriel 2d aurait dû être généré. Notez que l’EAD du didacticiel 2d est d’environ 57 000. Il s’agit du risque d’inondation annuel résiduel pour ces actifs, après l’intervention du PLPM.
Cahier d’exercices complet du BCA
Accédez à l’onglet « BCA ». Assurez-vous que le chemin du fichier de contrôle pour le didacticiel 2d est affiché en haut de la fenêtre, puis cliquez sur « Copier le modèle BCA ». Vous devriez voir un nouveau paramètre “cba_xls” défini dans le fichier de contrôle et votre fenêtre “BCA” devrait ressembler à ce qui suit :
Cliquez maintenant sur « Ouvrir » pour modifier le classeur BCA. Vous devriez voir l’onglet « smry » rempli d’informations du didacticiel 2d, notamment l’EAD de 57 000 $ calculé pour cette option. Remplissez les cellules d’entrée restantes sur l’onglet « smry » en spécifiant l’EAD de 2a et un taux d’actualisation de 4 % comme indiqué ci-dessous :
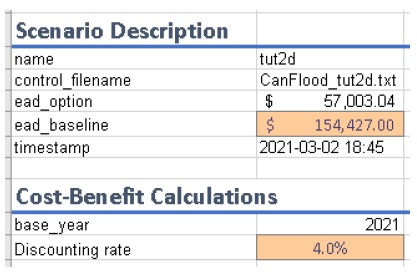
Passez maintenant à l’onglet « données » du classeur pour entrer les données avantages-coûts de la poursuite des atténuations du didacticiel 2d. Pour ce didacticiel, supposons que nous ayons déterminé les éléments suivants pour cette intervention :
L’installation des PLPM prendra 2 ans à 1 M$/an et assurera une protection de 100 ans ;
L’entretien coûtera 1 000 $/an à compter de la fin de la construction et se poursuivra pendant le cycle de vie de 100 ans de l’intervention ;
Il n’y aura aucun changement dans les avantages relatifs ou les coûts d’entretien au fil du temps.
Les deux lignes EAD de l’onglet « données » doivent être automatiquement renseignées en fonction des valeurs spécifiées dans l’onglet « smry » ; cependant, pour correspondre aux hypothèses ci-dessus, nous devons ajuster certaines de ces valeurs comme indiqué dans les six premières années de l’onglet « données » :
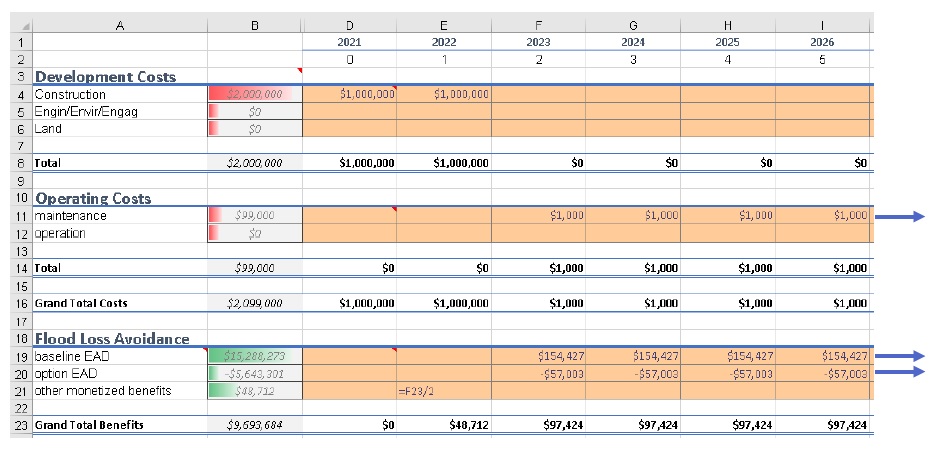
Notez que la première année de l’EAD « de base » et « option » sont vides, ce qui indique qu’aucun avantage n’a encore été obtenu ; cependant, la deuxième année montre que la moitié des avantages seront réalisés. Les coûts de maintenance de 1 000 $/an devraient s’étendre sur les 100 années complètes (c’est-à-dire, copier/coller sur toutes les cellules vers la droite - non illustré).
Une fois l’onglet « données » terminé, un « rapport B/C » de 1,18 devrait être affiché sur l’onglet « smry » 19. Enregistrez et fermez cette feuille de calcul.
Finance du tracé
Pour résumer et analyser davantage les données saisies dans la feuille de calcul BCA (assurez-vous d’appuyer sur Enregistrer !), revenez à la fenêtre CanFlood « BCA », sélectionnez « Valeurs futures » et cliquez sur « Plot Financials ». Le graphique ci-dessous doit être généré :
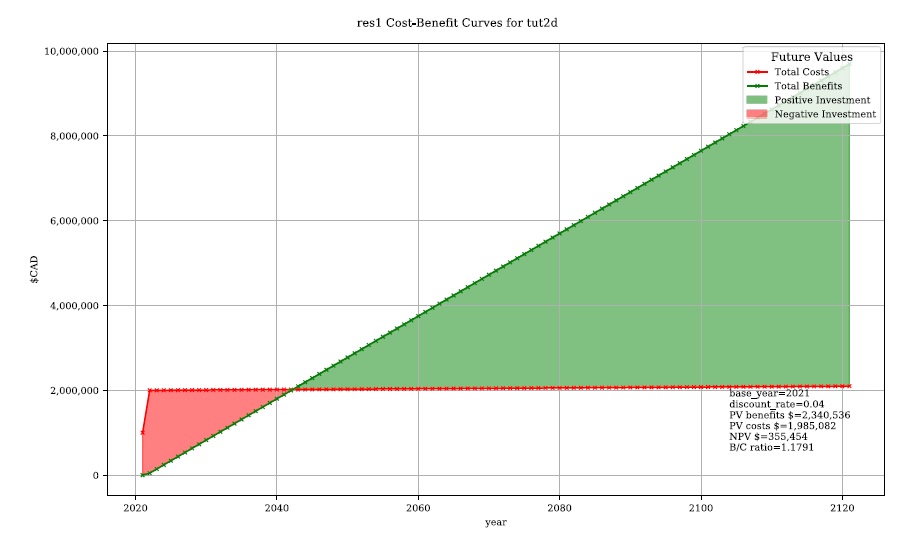
Cela montre les valeurs relatives des avantages et des coûts cumulés au fil du temps (sans actualisation). Notez que les coûts d’installation coûteux dépassent les avantages au départ ; cependant, après environ 25 ans, les avantages de cette option l’emportent sur les coûts (l”« année de retour sur investissement »). Notez également qu’avec les valeurs futures, le graphique montre des bénéfices cumulés d’environ 10 millions de dollars à 100 ans. Peut-être qu’à ce moment-là, nous vivrons tous dans des vaisseaux spatiaux… alors peut-être vaut-il mieux ne pas considérer les avantages aussi lointains de l’atténuation des inondations de manière si significative.
Remplacez le bouton radio par « Présenter les valeurs » et cliquez à nouveau sur « Plot Financials ». Vous devriez voir un graphique comme ci-dessous :
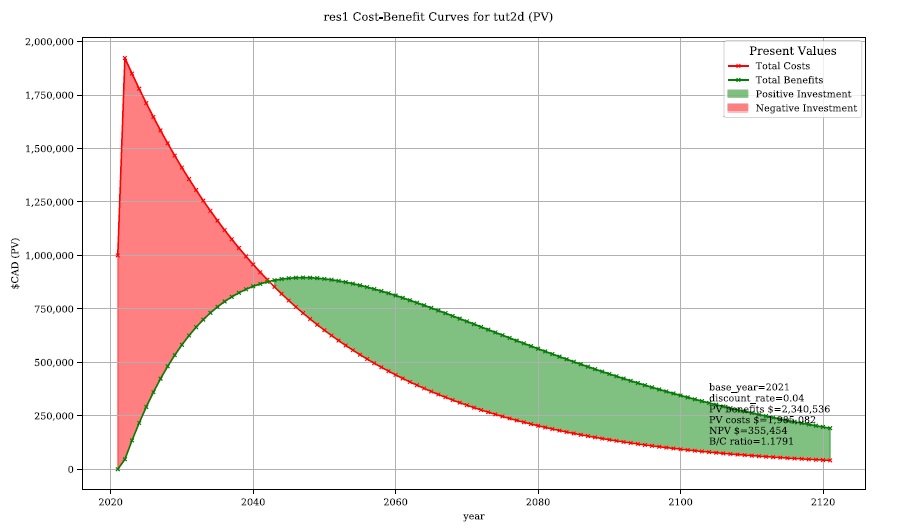
Notez que le « ratio B/C » et « l’année de remboursement » n’ont pas changé, mais le graphique montre maintenant que les coûts et les avantages diminuent avec le temps, reflétant l’application du taux d’actualisation.
Pour mieux comprendre le rôle du taux d’actualisation, revenez à la feuille de calcul, modifiez le taux d’actualisation à 8 %, enregistrez la feuille de calcul et, dans la fenêtre CanFlood, cliquez à nouveau sur « Plot Financials » :
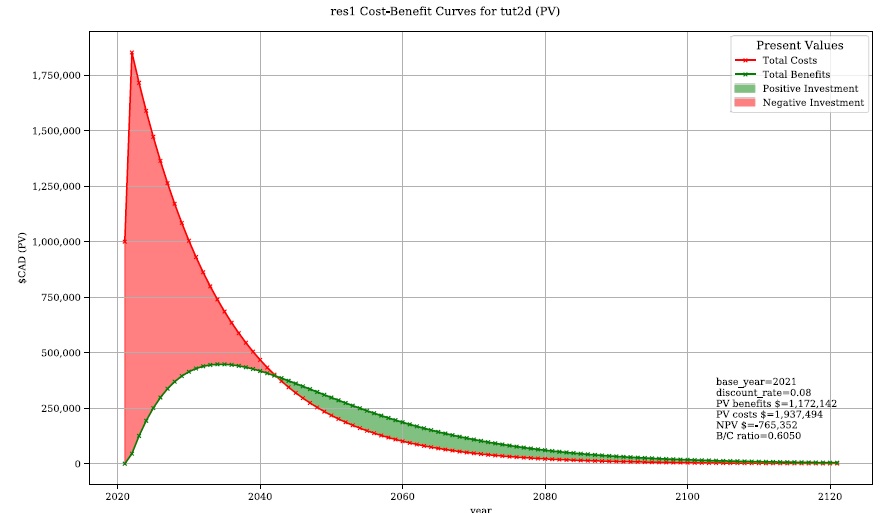
Notez que « l’année de récupération » n’a pas changé, mais la taille relative des zones positives (vertes) et négatives (rouges) a changé et le « ratio B/C » est tombé en dessous de 1. Cela reflète l’actualisation plus sévère du futur avantages apportés par le taux d’actualisation plus élevé de 8 %. En d’autres termes, au moment où les futurs résidents de la zone d’étude tirent des avantages significatifs des PLPM, les parties prenantes actuelles souhaiteraient avoir dépensé l’argent pour autre chose.
**************************************************** *************** 6.7. Tutoriel 3 : Modèle de recherche SOFDA Risque (L3) **************************************************** ***************
Des exemples d’entrées pour le modèle de recherche SOFDA sont fournis dans le dossier tutorials3. Reportez-vous à l”`Annexe B <appendix_b_>`__ pour plus d’informations.
**************************************************** *************** 6.8. Tutoriel 4a : Risque (L1) avec pourcentage d’inondation (polygones) **************************************************** ***************
Ce didacticiel présente une analyse des risques des actifs de type polygone où la métrique d’impact est le pourcentage d’inondation plutôt que la profondeur. Cela peut être utile pour certains modèles de risque grossiers, ou pour des actifs comme les champs agricoles où la perte peut raisonnablement être calculée à partir du pourcentage de l’actif qui est inondé.
Chargez les couches de données suivantes à partir du dossier “tutorials4data' :
haz_rast : rasters d’événements dangereux avec prédictions de valeurs WSL pour la zone d’étude pour quatre probabilités.
o haz_0050_tut4.tif
o haz_0100_tut4.tif
o haz_0200_tut4.tif
o haz_1000_tut4.tif
dtm_cT2.tif : couche DTM (et fichier .qlr de définition de couche stylisée correspondant)
finv_tut4a_polygons.gpkg : inondation de la couche spatiale d’inventaire des actifs (“finv”)
Déplacez la couche d’inventaire de polygones (“finv”) vers le haut, appliquez le style CanFlood “fill transparent blue” 20, et votre projet devrait ressembler à ceci 21 :
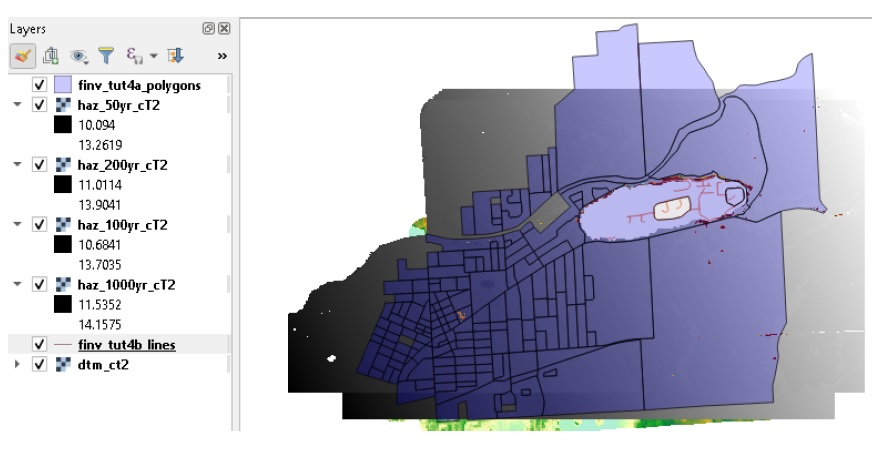
6.8.1. Construire le modèle
Installer
Lancez l’ensemble d’outils CanFlood “Build” et accédez à l’onglet “Setup”. Définissez le champ « Précision » 22 sur « 6 », puis effectuez la configuration typique comme indiqué dans le didacticiel 1a.
Inventaire
Accédez à l’onglet « Inventaire », assurez-vous que « Type d’élévation » est défini sur « Datum » 23 puis cliquez sur « Stocker ».
Échantillonneur de danger
Accédez à l’outil « Hazard Sampler », chargez les quatre rasters de danger dans la fenêtre de dialogue, cochez « Box plots », cochez « Exposition as Inundation% », définissez le « Seuil de profondeur » sur 0,5 et sélectionnez la couche DTM comme indiqué :
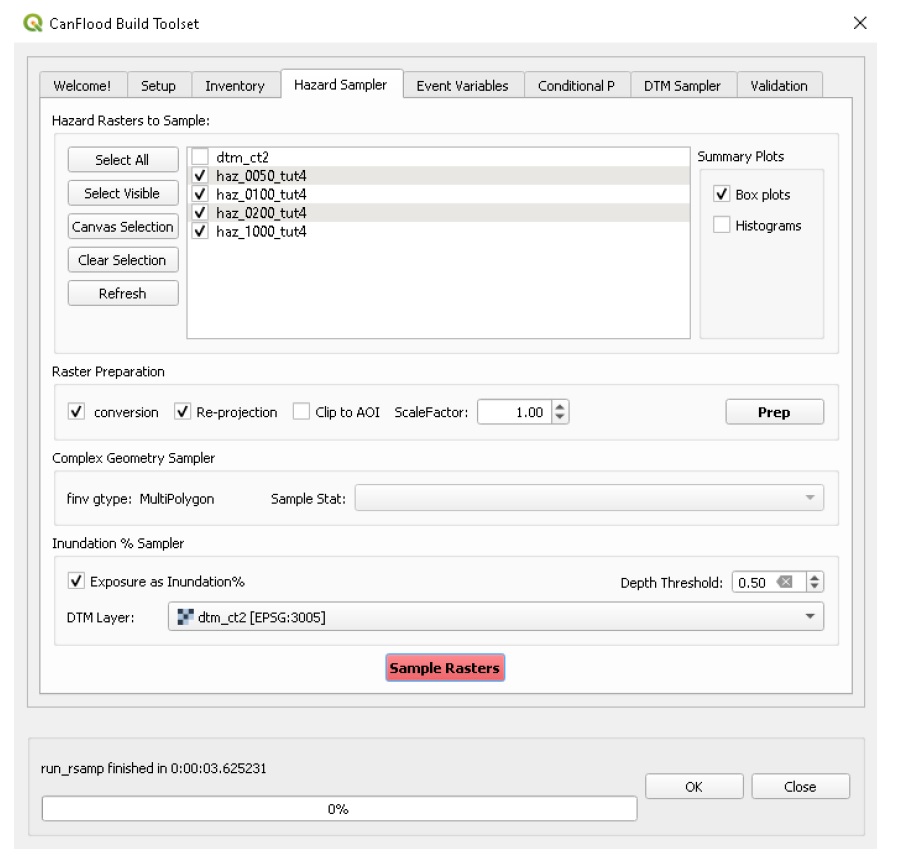
Cliquez sur « Exemple de rasters ». Accédez au fichier de données d’exposition (“expos”) créé dans votre répertoire de travail. Vous devriez voir un tableau comme celui-ci :
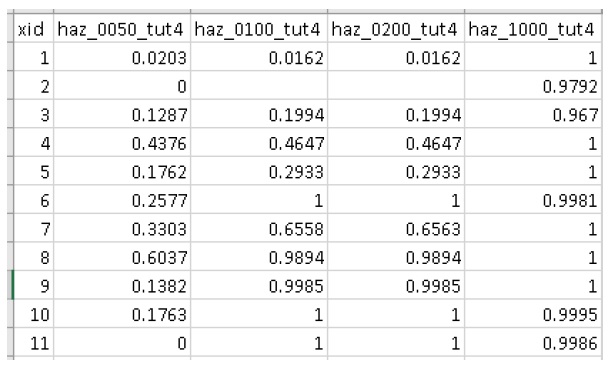
Ces valeurs sont le pourcentage calculé de chaque polygone avec une inondation supérieure au seuil de profondeur spécifié (0,5 m). Les boîtes à moustaches générées montrent ces données graphiquement :
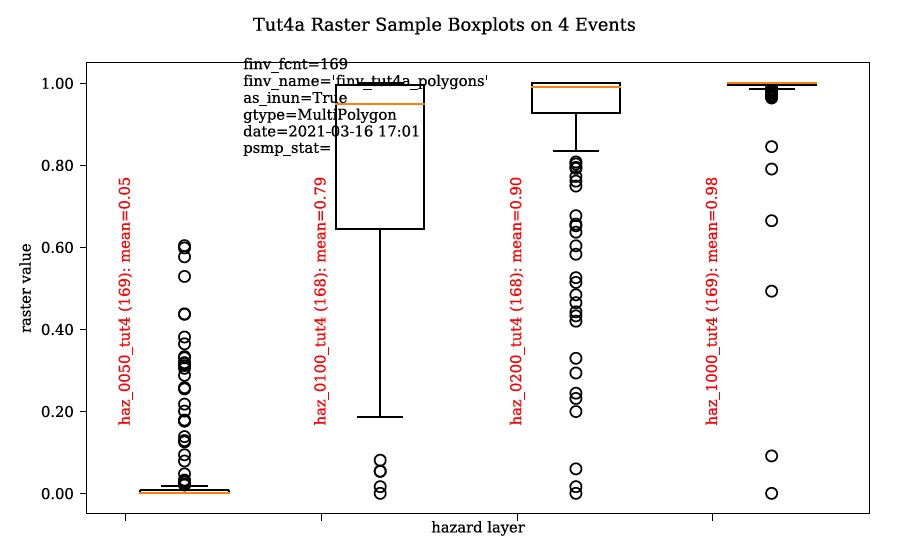
Variables d’événement et validation
Exécutez les outils « Variables d’événement » et « Validation » comme indiqué dans le didacticiel 1a.
6.8.2. Exécuter le modèle
Ouvrez la boîte de dialogue “Modèle” |runimage| et suivez les étapes du didacticiel 1a pour configurer cette exécution de modèle. Accédez à l’outil « Risk (L1) », cochez les cases affichées et cliquez sur « Exécuter le risque1 » :
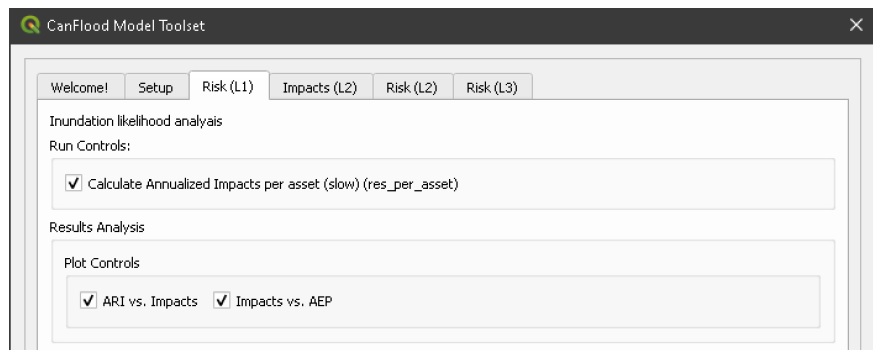
L’ensemble de fichiers de résultats discuté ci-dessous aurait dû être généré.
6.8.3. Voir les résultats
Accédez à votre répertoire de travail. Vous devriez voir que les fichiers de résultats suivants ont été générés :
risk1_run1_tut4_passet.csv : résultats par actif
risk1_run1_tut4_ttl.csv
tut4a run1 AEP-Impacts plot pour 6 events.svg
tut4a run1 Graph Impacts-ARI pour 6 events.svg
Ouvrez le fichier de données des résultats par actif (« passet »), il devrait ressembler à ceci :
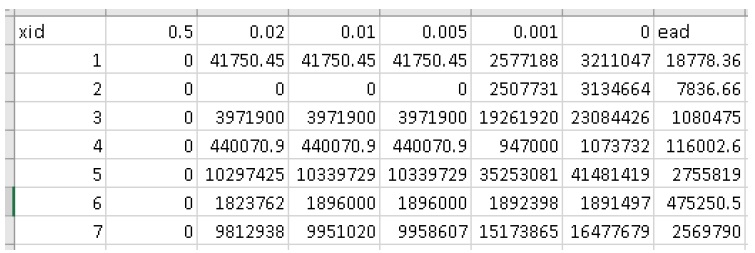
Les premières colonnes non indexées sont simplement le pourcentage d’inondation (issu du fichier de données « expos ») multiplié par l’attribut d’échelle de l’actif (issu du fichier de données « finv »). La dernière colonne “ead” est la valeur attendue de ces quatre colonnes.
Pour visualiser cela, ouvrez la boîte à outils “Résultats” et configurez l’onglet “Configuration” en sélectionnant le fichier de contrôle. Accédez à l’onglet « Rejoindre Geo » et configurez-le comme indiqué ci-dessous :
Cliquez sur “Rejoindre”. Vous devriez voir une nouvelle couche vectorielle de polygone chargée dans votre canevas avec un style gradué rouge et des étiquettes appliquées aux résultats EAD calculés à l’étape précédente :
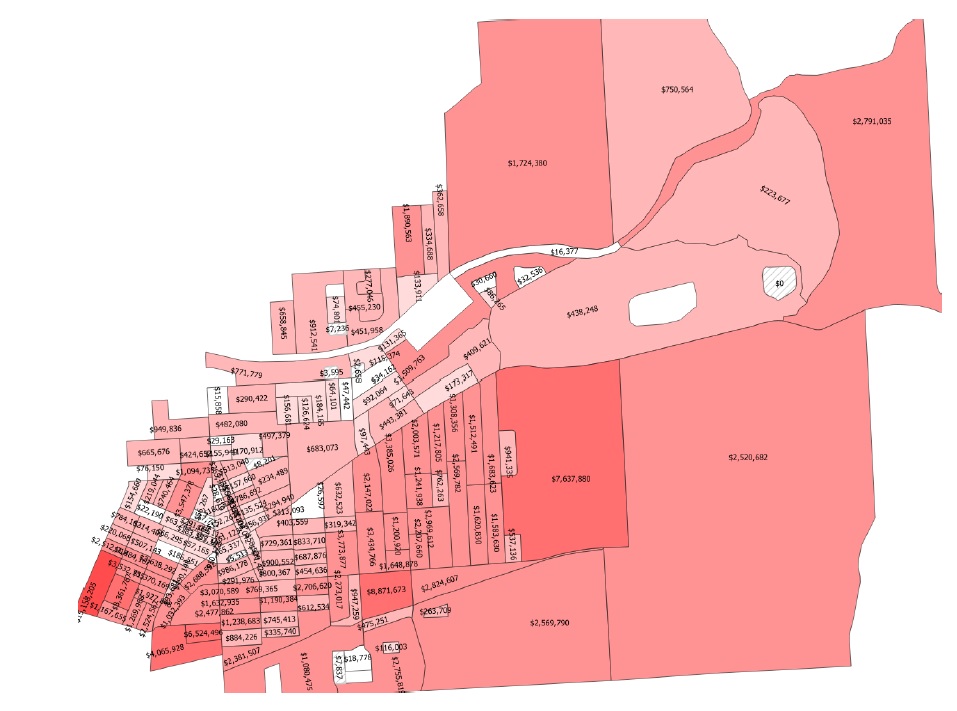
**************************************************** *************** 6.9. Tutoriel 4b : Risque (L1) avec pourcentage d’inondation (lignes) **************************************************** ***************
Comme le didacticiel 4a, ce didacticiel présente une analyse des risques dans laquelle la métrique d’impact est inondée en pourcentage, mais avec des géométries linéaires plutôt que des polygones. Cela peut être utile pour l’analyse du risque d’inondation pour les actifs linéaires comme les routes.
Chargez les mêmes couches de données à partir du dossier “tutorials4data', avec en plus :
finv_tut4b_lines.gpkg
Suivez toutes les étapes décrites dans le didacticiel 4a, mais avec cette nouvelle couche d’inventaire des actifs (“finv”).
Les résultats par actif devraient ressembler à ceci :
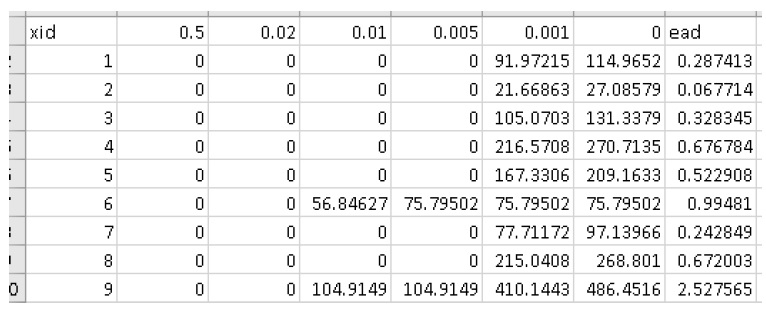
Les premières colonnes « impact » non indexées représentent les événements dangereux, avec des valeurs indiquant le pourcentage d’inondation de chaque segment multiplié par sa valeur « f0_échelle ». Cela pourrait représenter les mètres inondés (au-dessus du seuil de profondeur de 0,5 m) par segment, si la valeur “f0_scale” est la longueur du segment (comme c’est le cas avec l’inventaire du tutoriel). Alternativement, la valeur “f0_scale” pourrait être définie sur “1.0” pour toutes les caractéristiques, ce qui ferait en sorte que les valeurs refléteraient simplement le % d’inondation de chaque segment (reflétant la sortie de l’outil Hazard Sampler) et la dernière colonne calculerait le pourcentage attendu inondation annuelle du segment.
**************************************************** *************** 6.10. Tutoriel 5a : Risque (L1) de l’INRP et du GAR15 **************************************************** ***************
Ce didacticiel montre comment construire un modèle CanFlood « Risk (L1) » à partir de deux sources Web :
L’Inventaire national des rejets de polluants (INRP) <https://www.canada.ca/fr/services/environment/pollution-waste-management/national-pollutant-release-inventory.html>`__; et
Pour plus d’informations sur ces ensembles de données, voir `Appendice A <appendix_a_>`__.
Étant donné que ce didacticiel traite de données ayant des SCR disparates, les utilisateurs doivent être familiarisés avec la gestion native de QGIS des SCR de projet et de couche discutée ici <https://docs.qgis.org/3.10/en/docs/user_manual/working_with_projections/working_with_projections.html >`__.
6.10.1. Charger les données dans le projet
Commencez par définir le CRS de votre projet QGIS sur “EPSG:3978” (Projet > Propriétés > CRS > sélectionnez “EPSG:3978”) 25. Vous êtes maintenant prêt à télécharger, puis à ajouter, la couche de données pour le didacticiel 5 :
tut5_aoi_3978.gpkg : polygone AOI pour le didacticiel.
Définissez le style de calque de l’AOI sur « remplir de rouge transparent » pour vous permettre de voir à travers le polygone. Avant que la construction de l’inventaire puisse commencer, nous devons ajouter les données brutes de l’INRP et du GAR15 au projet QGIS. Bien qu’il existe de nombreuses options pour accéder à ces données et les importer, ce didacticiel montrera comment utiliser la fonction intégrée « Ajouter des connexions » de CanFlood |addConnectionsImage| (Section5.4.1_) pour ajouter d’abord une connexion au profil, puis téléchargez les couches souhaitées.
Connectez-vous à Web-Data
Commencez par développer le « Panneau du navigateur » de QGIS (Ctrl + 2), puis cliquez sur « Actualiser » dans le panneau. Cela devrait ressembler à ceci:
Cela montre toutes les connexions dans votre profil QGIS.
Ensuite, exécutez “Ajouter des connexions” |addConnectionsImage| (Plugins > CanFlood) pour exécuter un script qui tentera d’ajouter un ensemble de connexions supplémentaires à votre profil. Vos messages de journal devraient ressembler à ceci :
Ceci décrit chacune des connexions que CanFlood a ajoutées à votre profil. Pour vérifier cela, revenez au « Panneau du navigateur ». Vous devriez voir les connexions suivantes (sous chaque type de connexion) :
UNISDR_GAR15_GlobalRiskAssessment (WCS)
ECCC_NationalPollutantReleaseInventory_NPRI (ArcGIS Feature Service)
Notez que ces connexions resteront dans votre profil pour les futures sessions QGIS, ce qui signifie « Ajouter des connexions » |addConnectionsImage| l’outil ne devrait être requis qu’une seule fois par profil 26.
Télécharger les données de l’INRP
Maintenant que les connexions ont été ajoutées à votre profil, vous êtes prêt à télécharger les couches. Pour limiter la demande de données, assurez-vous que votre canevas de carte correspond à peu près à l’étendue de la zone d’intérêt 27. Ouvrez maintenant le “Data Source Manager” de QGIS (Ctrl + L) et sélectionnez “ArcGIS Feature Server”. Sélectionnez « ECCC_NationalPollutantReleaseInventory_NPRI » dans la liste déroulante sous « Connexions au serveur ». Cliquez sur “Connecter” pour afficher les couches disponibles sur le serveur. Sélectionnez la couche 3 « Rejets signalés dans les eaux de surface pour 2019 », cochez « Seulement les fonctionnalités de demande… », puis cliquez sur « Ajouter » pour ajouter la couche au projet comme indiqué ci-dessous :
Vous devriez maintenant voir une couche de points vectoriels ajoutée à votre projet avec des informations sur chaque installation déclarée à l’INRP (dans votre vue sur le canevas). Notez que le CRS de cette couche est EPSG:3978 (cliquez avec le bouton droit sur la couche dans le panneau « Calques » > Propriétés > Informations > CRS), cela devrait correspondre à votre projet QGIS et à l’AOI.
Télécharger les données GAR15
Suivez un processus similaire pour télécharger 28 les couches suivantes à partir de « UNISDR_GAR15_GlobalRiskAssessment » sous l’onglet « WCS », comme indiqué ci-dessous :
GAR2015 :flood_hazard_200_yrp
GAR2015 :flood_hazard_100_yrp
GAR2015 :flood_hazard_25_yrp
GAR2015 :flood_hazard_500_yrp
GAR2015 :flood_hazard_1000_yrp
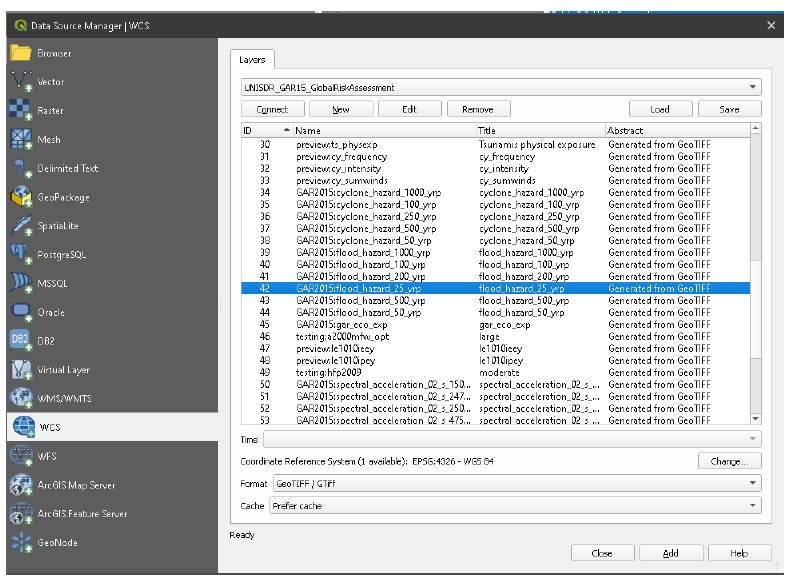
Vous devrez charger une couche à la fois et vous serez peut-être invité à « Sélectionner la transformation » 29. Une fois terminé, votre toile devrait ressembler à ceci :
6.10.2. Construire le modèle
Cette section décrit comment terminer la construction d’un modèle de risque (L1) à partir des données téléchargées de l’INRP et du GAR15. Pour obtenir des instructions sur le reste du processus de modélisation du risque (L1), voir la Section 6.1_.
Installer
Suivez les instructions de la Section 6.1.2_ Configuration ; cependant, assurez-vous que « tut5_aoi_3978 » est sélectionné sous « AOI du projet » et « Charger les résultats de la session… » est sélectionné.
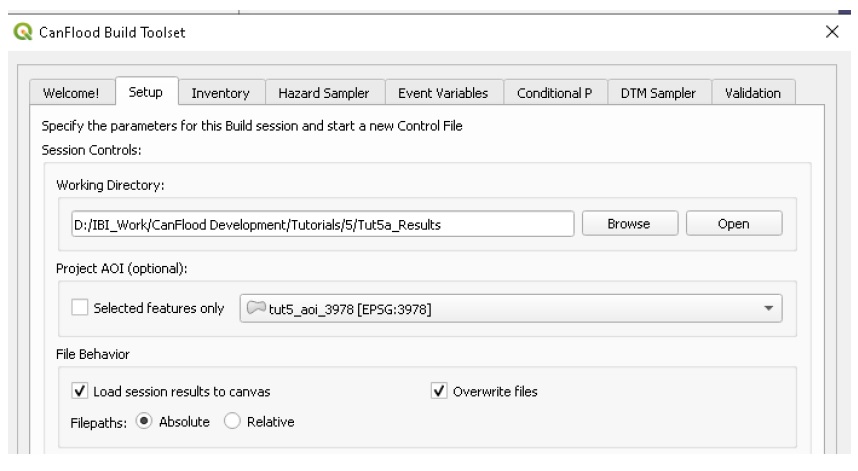
Construire et stocker l’inventaire
Accédez à l’onglet « Inventaire ». Pour convertir les données téléchargées de l’INRP en une couche d’inventaire L1 que CanFlood reconnaîtra, nous devons ajouter les champs et les valeurs « elv » et « scale ». Pour cette analyse simple, nous supposons que chaque actif a une hauteur de vulnérabilité de zéro (c’est-à-dire que toute profondeur d’inondation positive entraîne une exposition). Cette hypothèse est accomplie dans CanFlood en définissant “felv”= “datum” et en définissant chaque “f0_elv”=0 (et en utilisant la profondeur plutôt que les rasters WSL). À l’aide du menu déroulant Couche vectorielle, sélectionnez la couche NPRI et assurez-vous que les champs « nestID », « scale » et « elv » correspondent à ce qui est indiqué ci-dessous. Enfin, cliquez sur « Construire finv » pour créer la nouvelle couche d’inventaire. Pour générer le fichier csv d’inventaire des actifs (« finv »), assurez-vous que cette nouvelle couche est sélectionnée dans la liste déroulante « Couche vectorielle d’inventaire ». Configurez maintenant les paramètres “felv” et “cid” comme indiqué ci-dessous,
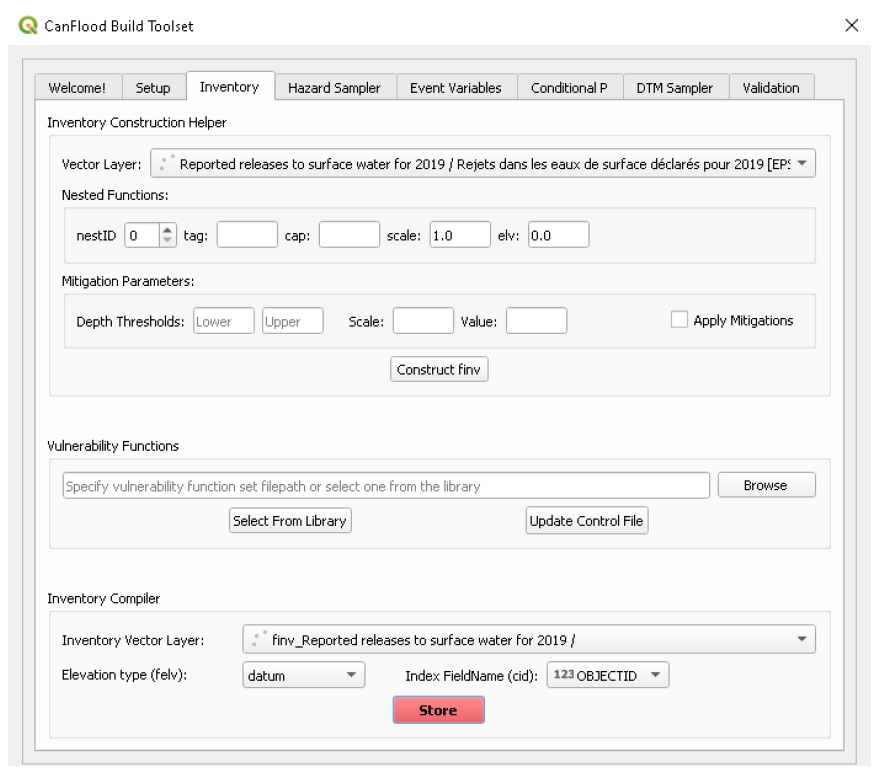
Échantillonneur de danger
Vous êtes maintenant prêt à échantillonner les couches de danger GAR15 avec votre nouvel inventaire de l’INRP. Contrairement aux couches de danger utilisées dans les didacticiels précédents, les couches de danger GAR15 fournissent des données de profondeur (plutôt que WSL) en centimètres (plutôt qu’en mètres) dans un système de coordonnées autre que celui de notre projet. De plus, l’étendue de ces couches d’aléas est beaucoup plus grande que ce dont notre projet a besoin ; et parce qu’il s’agit de couches Web, de nombreux outils de traitement QGIS ne fonctionneront pas. Par conséquent, nous devrons appliquer les quatre outils de « Préparation de raster » décrits dans le Tableau 5-2 avant de passer à l”« Échantillonneur de dangers ».
Accédez à l’onglet « Hazard Sampler », assurez-vous que les cinq couches GAR2015 sont répertoriées dans la fenêtre, puis cliquez sur « Sample ». Vous devriez obtenir une erreur vous indiquant que la couche CRS ne correspond pas à celle du projet. Pour résoudre ce problème, configurez les poignées de préparation de raster comme indiqué et cliquez sur « Préparer » :
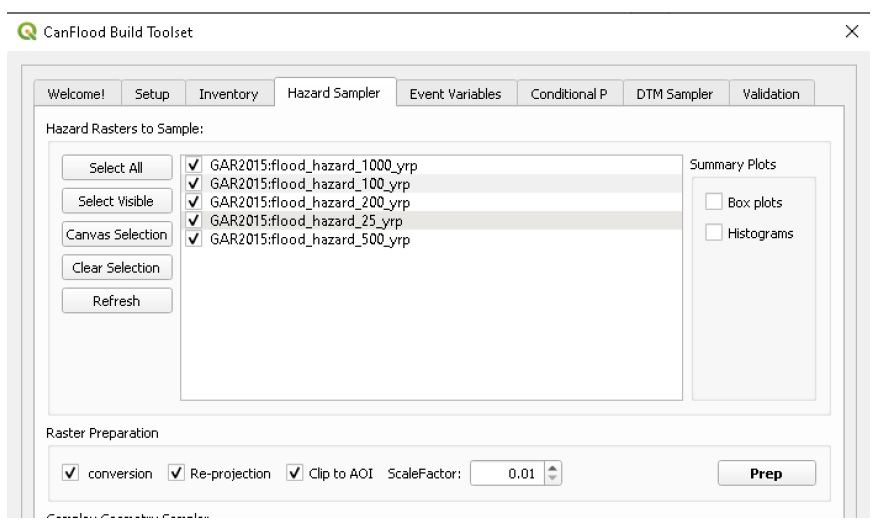
Vous devriez voir cinq nouveaux rasters chargés sur votre canevas (avec un suffixe “prepd”). Ces couches doivent avoir des pixels pivotés, être découpées sur l’AOI, avoir des valeurs de profondeur d’inondation raisonnables (en mètres) et avoir le même CRS que le projet 30. De plus, chacun de ces rasters doit être enregistré dans votre répertoire de travail. Ce nouvel ensemble de couches de danger doit être conforme aux attentes de l’échantillonneur de danger, vous permettant de procéder à la construction d’un modèle L1 comme décrit dans la section 6.1_.
**************************************************** *************** 6.11. Tutoriel 6a : Polygones de rupture de digue **************************************************** ***************
Ce didacticiel montre comment générer des « polygones de rupture » à partir d’informations typiques sur les digues à l’aide de l’outil « Dike Fragility Mapper » de CanFlood (Section5.4.1_). Avant de suivre ce didacticiel, les utilisateurs doivent se familiariser avec les types de données d’événements dangereux décrits dans la section 4.2_ (en particulier les « polygones de défaillance ») qui sont requis pour les modèles de risque (L1) et (L2) avec quelques défaillances. Commencez par télécharger les données du didacticiel à partir du dossier tutorials6 et chargez-le dans un nouveau projet QGIS :
rasters d’événements WSL de danger (sans échec)
o 0010_noFail.tif
o 0050_noFail.tif
o 0200_noFail.tif
o 1000_noFail.tif
dike_influence_zones.gpkg : Couche de zone d’influence de segment de digue avec deux entités surfaciques, chacune correspondant à la zone d’influence de certains segments de digue ;
dikes.gpkg : couche de polylignes d’alignement de digues
dtm.tif : Modèle numérique de terrain (importer “dtm.qlr” pour obtenir la version stylisée) ;
dike_fragility_20210201.xls : bibliothèque de fonctions de fragilité des digues.
Voir Section 4.5_ pour une description de ces ensembles de données. Assurez-vous que le CRS de votre projet est défini sur “EPSG:3005”. Une fois les couches SIG chargées, votre canevas de carte devrait ressembler à ce qui suit :
Pour rendre cet espace de travail plus convivial, assurez-vous que les calques “dikes” et “dike_influence_zones” sont en haut du panneau des calques. Appliquez maintenant les styles CanFlood 31 suivants à chacune de ces couches :
digues : “flèche noire”
dike_influence_zones : “remplir rouge transparent”
Le style de flèche est utile car nous aurons besoin de connaître la directionnalité de la couche de digue pour indiquer à l’outil quel côté de la digue échantillonner. Nous sommes maintenant prêts à ouvrir la boîte de dialogue « Dike Fragility Mapper » :
Configurez votre boîte de dialogue de la même manière que celle illustrée ci-dessous, mais en utilisant vos propres répertoires (assurez-vous que « dikeID » est défini sur « ID »):
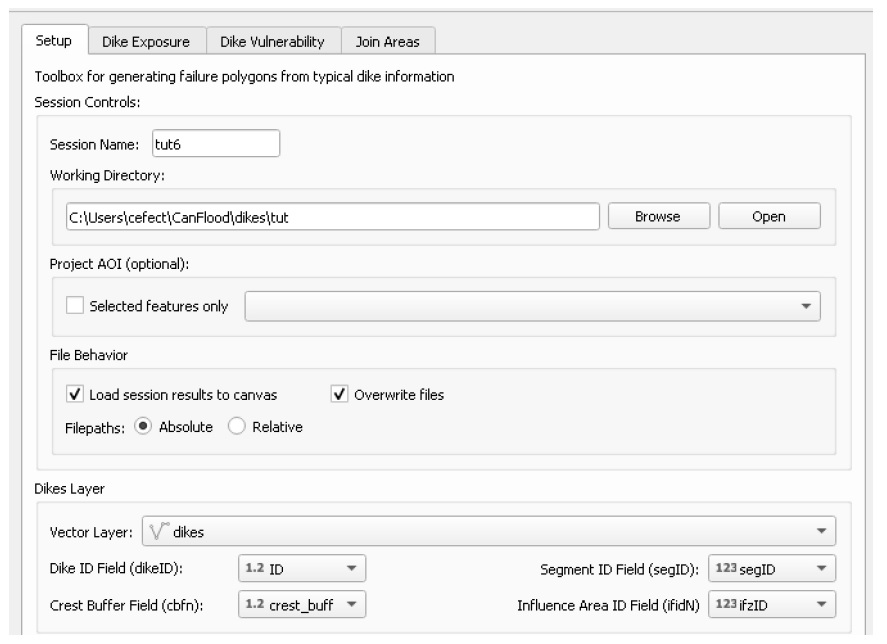
6.11.1. Calculer l’exposition de la digue
Cette étape calculera les valeurs d’exposition, ou franc-bord, de chaque segment de digue. Accédez à l’onglet « Dike Exposure », cliquez sur « Refresh », puis configurez-le comme indiqué ci-dessous, en prenant soin de sélectionner la couche DTM dans la liste déroulante, mais pas dans la fenêtre de sélection :
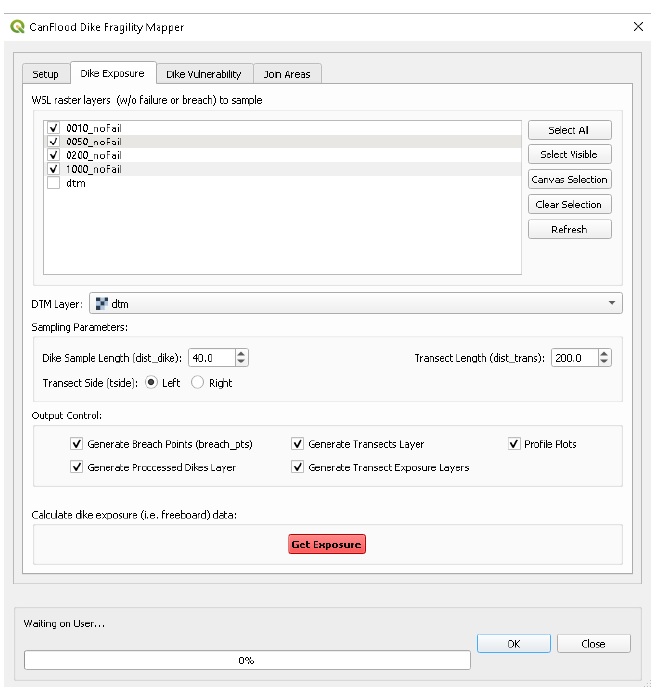
Cliquez sur “Obtenir une exposition”. Vous devriez voir 10 couches chargées sous le groupe « CanFlood.Dikes » :
tut6_dike_dikes : couche de digues traitées
couches de points de rupture (pour chaque événement)
o 0010_noFail_breach_1_pts
o 0050_noFail_breach_3_pts
o 0200_noFail_breach_16_pts (voir ci-dessous |diamondimage| )
o 1000_noFail_breach_50_pts
tut6_tut6_dike_dikes_transects : couche de transects (voir ci-dessous |lineimage|)
couches de points d’exposition de transect
o tut6_dike_dikes_0010_noFail_expo
o tut6_dike_dikes_0050_noFail_expo
o tut6_dike_dikes_0200_noFail_expo (voir ci-dessous |dotimage| )
o tut6_dike_dikes_1000_noFail_expo
Ces types de couches sont expliqués dans la Section 6.11_, et ceux pertinents pour la série de 200 ans sont affichés ci-dessous. La longueur d’échantillon de 40 m de digue et la longueur de transect de 200 m que nous avons spécifiées dans la boîte de dialogue peuvent être vues dans l’espacement et la longueur des transects indiqués ci-dessous :
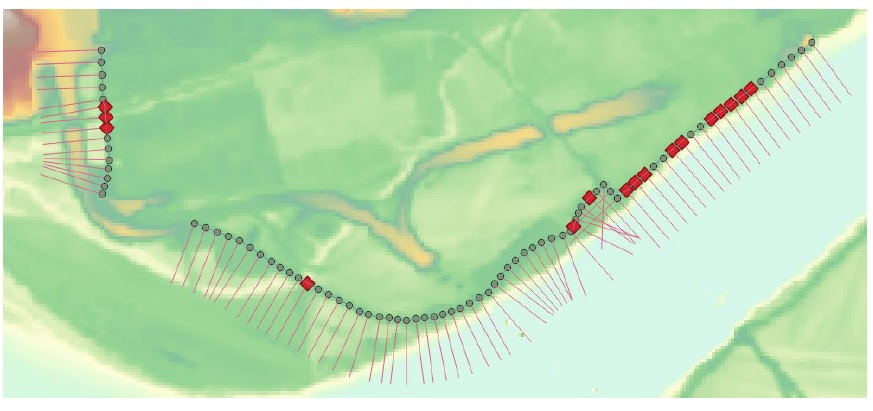
À la base, cet outil échantillonne le raster WSL à la queue de chaque transect et le MNT à la tête, puis les compare pour calculer le franc-bord. Cela suggère que l’utilisateur doit spécifier un côté de transect, une longueur d’échantillon et une longueur de transect appropriés en fonction de la configuration de l’endiguement et de l’inondation pour obtenir un calcul de franc-bord précis.
Pour visualiser les valeurs de franc-bord calculées, appliquez des « étiquettes uniques » pour les valeurs « sid » sur la couche de digues traitée, puis accédez à votre répertoire de travail et ouvrez le fichier image “tut6 dike 43-1 profiles.svg”. Cela devrait ressembler à ce qui suit :
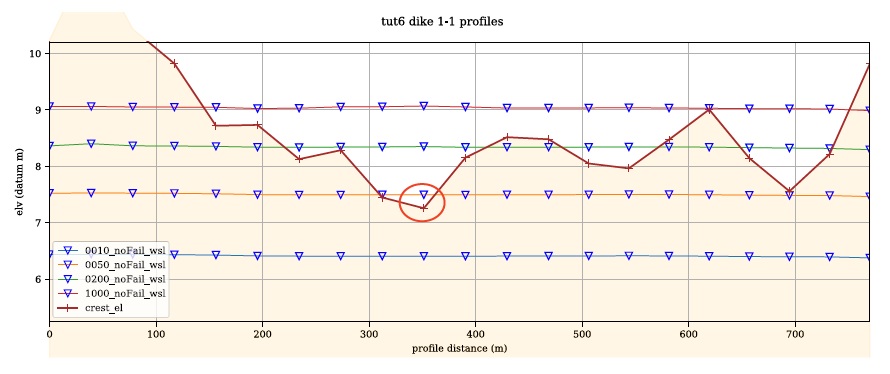
Il s’agit d’un tracé de profil de la digue 43, segment 1 (sid=4301) montrant l’élévation de la crête calculée et le WSL pour les quatre rasters d’événements (échantillonnés avec chaque transect). Notez que, ce graphique suggère que le franc-bord du 50 ans soit d’environ -0,2 m (voir cercle rouge ci-dessus). Ouvrez maintenant le fichier “tut6_dExpo_7_3.csv” dans le répertoire de travail, il s’agit de l’ensemble de données d’exposition du segment de digue (“dexpo”) que nous utiliserons à l’étape suivante pour calculer les probabilités de défaillance. Notez que la valeur de franc-bord du segment-événement en question est de -0,2 m comme prévu :

6.11.2. Calculer la vulnérabilité de la digue
Cette étape utilisera les valeurs de franc-bord précédemment calculées et les courbes de fragilité fournies par l’utilisateur pour calculer la probabilité de défaillance de chaque segment. Passez à l’onglet « Dike Vulnerability », vous devriez voir le chemin d’accès aux résultats d’exposition ci-dessus automatiquement renseigné dans le champ « dexpo_fp ». Sélectionnez maintenant le fichier “dike_fragility_20210201.xls” de la bibliothèque de courbes de fragilité fourni avec les données du didacticiel. Les noms d’onglets de ce classeur correspondent au champ « f0_dtag » sur la couche des digues, indiquant à CanFlood quelle courbe appliquer à quel segment. Choisissez “Aucun” pour les corrections d’effet de longueur. Votre boîte de dialogue devrait ressembler à ceci :
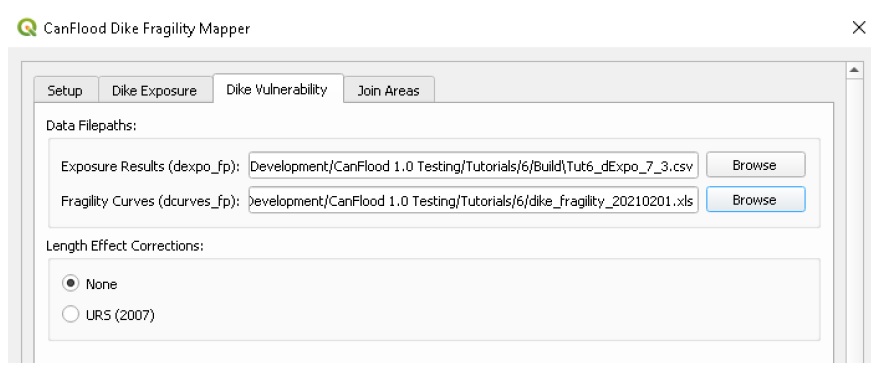
Cliquez maintenant sur « Calc Fragilité » pour générer les données tabulaires de probabilité de défaillance (« pfail »).
6.11.3. Joindre aux zones
Dans cette dernière étape, nous joindrons les probabilités de rupture précédemment calculées aux zones d’influence fournies par l’utilisateur pour chaque segment en fonction des liens fournis sur la couche des digues. Accédez à l’onglet « Rejoindre les zones ». Vous devriez voir le chemin du fichier de données « pfail » dans le champ correspondant ; sinon, accédez à ce fichier. Si vous avez exécuté avec succès l’outil « Dike Exposure » cette session, vous devriez voir la première colonne de couches raster sélectionnée ; sinon, sélectionnez manuellement les quatre rasters WSL dans la première colonne. Pour la deuxième colonne, sélectionnez la couche de polygones « dike_influence_zone » dans la première liste déroulante, puis cliquez sur « Remplir vers le bas » pour remplir les listes déroulantes restantes. Une fois terminé, votre boîte de dialogue devrait ressembler à ce qui suit :
Cliquez sur “Map pFail”. Vous devriez voir quatre couches de polygones chargées sur votre toile, une pour chaque événement. Déplacez ces couches vers le haut dans la liste des couches afin qu’elles s’affichent au-dessus des rasters. L’année 200 est indiquée ci-dessous :
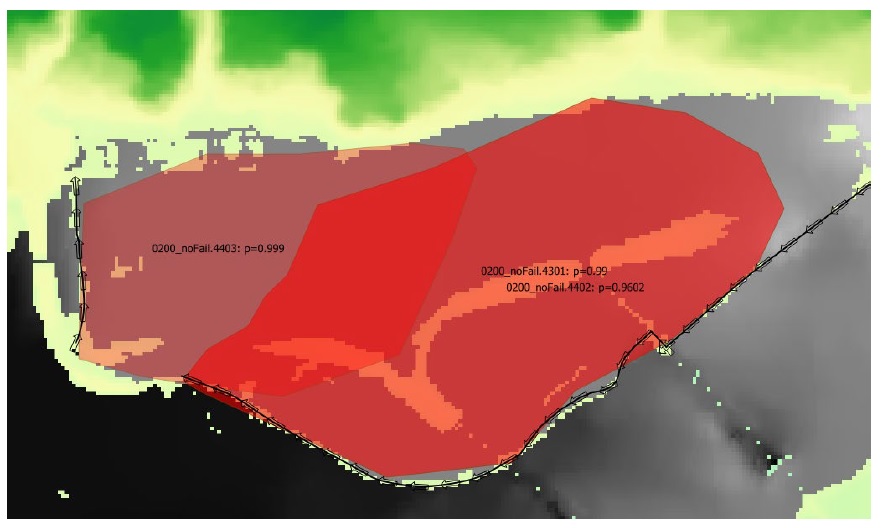
Ces couches de résultats sont automatiquement stylisées sous forme de polygones de défaillance, affichant le nom du raster d’événements, le segment de digue source (“sid”) et la probabilité de défaillance de chaque entité. Notez que la période de 200 ans contient 3 entités surfaciques qui se chevauchent correspondant aux trois segments avec défaillance ici, malgré le fait que la couche d’origine « dike_influznce_zones » comporte deux entités. Cette cartographie des polygones aux segments de digues est définie sur la couche des digues dans le « Champ d’identification de la zone d’influence » spécifié dans l’onglet « Configuration » (« ifzID » dans ce cas). De cette façon, des liens 1:1 ou plusieurs:plusieurs segments-polygones peuvent être spécifiés, permettant à l’utilisateur de cartographier chaque probabilité de rupture, ou de grouper des segments pour appliquer les probabilités calculées à un anneau de digue plus grand. Voir Section 5.4.1_ pour plus d’informations sur cet outil.
Les références
Bedford, T., et Roger M. Cooke. 2001. Analyse probabiliste des risques : fondements et méthodes. Cambridge, Royaume-Uni ; New York, NY, États-Unis : Cambridge University Press.
Bryant, Seth. 2019. « Accumulation du risque d’inondation ». Université de l’Alberta. https://era.library.ualberta.ca/items/1e033c0d-6c4c-4749-9195-e46ce9eb3e2b.
Farber, Daniel A. 2016. « Taux d’actualisation et sécurité des infrastructures : implications du nouvel apprentissage économique ». Dans Risk Analysis of Natural Hazards, édité par Paolo Gardoni, Colleen Murphy et Arden Rowell, 43-57. Cham : Éditions internationales Springer. https://doi.org/10.1007/978-3-319-22126-7_4.
FEMA. 2012. « Méthodologie d’estimation des pertes multirisques, modèle d’inondation : manuel technique Hazus-MH MR2 ». FEMA Washington, DC. https://www.fema.gov/media-library-data/20130726-1820-25045-8292/hzmh2_1_fl_tm.pdf.
Fréchette, Jean-Denis. 2016. « Estimation du coût annuel moyen des accords d’aide financière en cas de catastrophe en raison d’événements météorologiques ».
Hosin, Adam. 2016. « Déontologie et risques naturels. Dans Risk Analysis of Natural Hazards, édité par Paolo Gardoni, Colleen Murphy et Arden Rowell, 137-53. Cham : Éditions internationales Springer. https://doi.org/10.1007/978-3-319-22126-7_9.
Groupe IBI et Golder Associates. 2015. « Étude provinciale sur l’évaluation des dommages causés par les inondations ». Gouvernement de l’Alberta. https://open.alberta.ca/publications/7032365.
IWR et USACE. 2017. « Principes d’analyse des risques pour les ressources en eau. »
Merz, B., H. Kreibich, R. Schwarze et A. Thieken. 2010. « Examen de l’article « Évaluation des dommages économiques causés par les inondations ». » Risques naturels et sciences du système terrestre 10 (8) : 1697-1724. https://doi.org/10.5194/nhess-10-1697-2010.
Messner, Frank. 2007. « FLOODSite : Evaluation des dommages causés par les inondations : orientation et recommandations sur les principes et les méthodes ». T09-06-01. Helmholz Unweltforschungszentrum (UFZ). http://repository.tudelft.nl/view/hydro/uuid:5602db10-274c-40da-953f-34475ded1755/.
Conseil National de Recherche. 2015. Lier l’assurance contre les inondations au risque d’inondation pour les structures de faible altitude dans la plaine inondable. Presse des Académies nationales.
O’Connell, PE, et G. O’Donnell. 2014. « Vers une modélisation de l’investissement dans la protection contre les inondations en tant que système humain et naturel couplé. » Hydrologie et sciences du système terrestre 18 (1) : 155–71. https://doi.org/10.5194/hess-18-155-2014.
Penning-Rowsell, Edmund, Sally Priest, Dennis Parker, Joe Morris, Sylvia Tunstall, Christophe Viavattene, John Chatterton et Damon Owen. 2013. Gestion des risques d’inondation et d’érosion côtière - Manuel. Routledge. https://www.mcm-online.co.uk/manual/.
Penning-Rowsell, Edmund, Sally Priest, Dennis Parker et d’autres. 2019. Gestion des risques d’inondation et d’érosion côtière - Manuel. 1ère éd. Routledge. https://doi.org/10.4324/9780203066393.
Sécurité publique Canada. 2018. « Série de lignes directrices fédérales sur la cartographie des inondations ». 21 décembre 2018. https://www.publicsafety.gc.ca/cnt/mrgnc-mngmnt/dsstr-prvntn-mtgtn/ndmp/fldpln-mppng-fr.aspx.
Rudari, Roberto et Francesco Silvestro. 2015. « AMÉLIORATION DU MODÈLE GLOBAL INONDATION POUR LA GAR 2015. » UNISDR. https://www.preventionweb.net/english/hyogo/gar/….
Sayers, Paul B., éd. 2012. Risque d’inondation : Planification, conception et gestion de l’infrastructure de défense contre les inondations. Londres : Éditions ICE.
Smith, Nicky, Charlotte Brown, ., et Wendy Saunders. 2016. « Prise de décision en matière de gestion des risques de catastrophe : examen. »
UNISDR, mai. 2009. « Terminologie de l’UNISDR pour la réduction des risques de catastrophe ».
URSS. 2008. « Stratégie de gestion des risques Delta (DRMS) Phase 1 - Vulnérabilité des digues - Final. » Département californien des ressources en eau.
USACE. 1996. « Analyse basée sur les risques pour les études de réduction des dommages causés par les inondations. » EM 1110-2-1619. https://www.publications.usace.army.mil/Portals/76/Publications/EngineerManuals/EM_1110-2-1619.pdf.
Notes de bas de page
- 1
Toutes les entrées SOFDA doivent être construites et configurées manuellement.
- 2
Les valeurs “plafonnées” avec traitement nul et arrondi.
- 3
Peut être construit à partir d’un fichier .xls en exportant vers csv puis en créant une couche csv dans QGIS à partir des valeurs lat/long.
- 4
Une simple courbe $/m2 correspondante est créée par le DamageCurves Converter.
- 5
Selon vos paramètres, cela peut avoir été défini automatiquement lorsque vous avez chargé les fichiers de données.
Tous les tutoriels utilisent CRS “EPSG:3005” sauf indication contraire. Voir le lien suivant pour une explication des projections dans QGIS.
- 6
En fonction de vos paramètres QGIS, il peut vous être demandé de sélectionner une transformation si le CRS n’a pas été réglé correctement au préalable.
- 7
Tout champ avec des valeurs entières uniques peut être utilisé comme index de nom de champ (à l’exception des identificateurs de fonction intégrés).
- 8
Si les couches de danger ne sont pas affichées dans la boîte de dialogue, appuyez sur « Actualiser ».
- 9
ne doit pas nécessairement correspondre au répertoire de l’étape précédente.
- 10
CanFlood tentera d’identifier automatiquement la couche vectorielle d’inventaire ; cependant, ce tutoriel fait n’utilisez pas cette couche afin que la sélection ici puisse être ignorée.
- 11
Si le chemin du fichier ne parvient pas à se remplir automatiquement, essayez de modifier la réinitialisation du “finv” et du “paramètre”
déroulants. Vous pouvez également saisir manuellement le chemin du fichier.
- 12
Certains outils “Résultats” fonctionnent mieux lorsque les fichiers de données de sortie du modèle se trouvent dans la même arborescence de fichiers que le Fichier de contrôle.
- 13
Essayez à nouveau d’exécuter l’outil, mais cette fois en sélectionnant “Max”. Si vous regardez attentivement les boxplots, vous devriez
voir une légère différence dans les probabilités résolues. Cela suggère que ce modèle n’est pas très sensible à l’hypothèse relationnelle de ces polygones de défaillance qui se chevauchent.
- 14
Alternativement, l’outil “Comparer” peut être utilisé pour générer un graphique de comparaison entre les deux tutoriels.
- 15
Les utilisateurs avancés pourraient éviter de réexécuter le modèle « Impacts (L2) » en manipulant le fichier de contrôle pour pointer aux résultats « dmgs » de l’exécution précédente car ceux-ci ne changeront pas entre les deux formulations.
- 16
Le fichier de contrôle spécifié dans l’onglet “Configuration” sera utilisé pour les styles de tracé courants (par exemple,
- 17
L’influence des fonctions d’atténuation sur les profondeurs n’est pas reflétée dans cette sortie.
- 18
Alternativement, le “tut2d_noMiti” du Tutoriel 2d peut être utilisé.
- 19
Si vous obtenez un ratio B/C de 1,19, assurez-vous que les coûts d’entretien de 1000 $ sont entrés pour chaque année du cycle de la vie.
- 20
Disponible dans le package de styles CanFlood décrit dans la section 5.4.4 (Plugins > CanFlood > Ajouter des styles).
- 21
Assurez-vous de charger les calques “.qlr” stylisés à la place des calques bruts.
- 22
Ceci est important pour l’analyse du pourcentage d’inondation qui traite de petites fractions.
- 23
Les exécutions de pourcentage d’inondation de risque (L1) ne peuvent pas utiliser les élévations d’actifs ; par conséquent, cette variable d’entrée est
redondant. Lorsque as_inun=True, les routines de modèle CanFlood s’attendent à une colonne “elv” avec tous des zéros.
- 24
Voir Rudari et Silvestro (2015) pour des détails sur le modèle d’aléa inondation GAR15.
- 25
Selon les paramètres de votre profil, le CRS du projet peut être automatiquement défini par le premier calque chargé.
- 26
Les nouvelles installations de Qgis devraient automatiquement accéder au même répertoire de profil (Paramètres > Profils utilisateur > Ouvrez le dossier de profil actif), reportant ainsi vos informations de connexion précédentes.
- 27
Ctrl+Maj+F zoomera sur l’étendue du projet.
- 28
Selon votre connexion Internet, ce processus peut être lent. Il est recommandé de définir “Cache”=”Prefer cache” pour limiter les transferts de données supplémentaires et pour désactiver les calques ou désactiver le rendu une fois chargés dans le projet.
- 29
Vous pouvez sélectionner en toute sécurité n’importe quelle transformation ou fermer la boîte de dialogue. Ces transformations sont uniquement destinées à l’affichage, nous traiterons de la transformation des données sur notre CRS ci-dessous.
- 30
Dans certains cas, QGIS peut ne pas reconnaître le SCR attribué à ces nouveaux rasters, indiqué par un « ? » montré à
à droite du calque dans le panneau des calques. Dans ces cas, vous devrez définir la projection en allant dans les “Propriétés” de la couche et sous “Source” définir le système de coordonnées pour qu’il corresponde à celui du projet (EPSG : 3978).
- 31
Chargez ces styles sur votre profil en utilisant l’outil Plugins>CanFlood>Ajouter des styles décrit dans la Section 5.4.4.
Annexe A : Connexions Web
+—————-+——————————— ———————–+———————–+— —————+ | Acronyme | Descriptif | Services | Référence | +===============+================================= =======================+======================+=== ================+ | UNISDR_GAR15_GlobalRiskAssessment | +—————-+——————————— ———————–+———————–+— —————+ | GAR15 | Les couches de données de l’UNISDR issues de l’évaluation globale des risques | WCS | voir ci-dessous | | | réalisé pour le rapport d’évaluation mondial le | | | | | Réduction des Risques de Catastrophes 2015 (GAR15) par la CIMA | | | | | Fondation de la recherche. Ces données sont hébergées par le | | | | | Global Risk Data Platform et contient six | | | | | rasters de profondeur de crue (en cm ; périodes de retour = 25, 50, | | | | | 100, 200, 500, 1000 ans) ayant une résolution de 1 km. | | | +—————-+——————————— ———————–+———————–+— —————+ | ECCC_NationalPollutantReleaseInventory_NPRI | +—————-+——————————— ———————–+———————–+— —————+ | INRP | Service de collecte de renseignements du gouvernement du Canada | ArcGisFeatureServer | page d’accueil | | | sur la libération, l’élimination et le transfert de plus de 320 | | | | | substances. Le service Web fournit des rapports de version | | | | | de l’année la plus récente. La couche “INRP-Reporting | | | | | Installations” montre l’emplacement des facilite | | | | | signaler tout type de rejet. | | | +—————-+——————————— ———————–+———————–+— —————+ | RNCan_NationalHumanSettlementLayer_NHSL | +—————-+——————————— ———————–+———————–+— —————+ | LNH | Collection d’ensembles de données thématiques qui décrivent | ArcGisFeatureServer | MapServer | | | caractéristiques physiques, sociales et économiques de | | | | | centres urbains et communautés rurales/éloignées à travers | | | | | Canada et leur vulnérabilité aux aléas naturels | | | | | de préoccupation | | | +—————-+——————————— ———————–+———————–+— —————+ | RNCan_AutomaticallyExtractedBuildings | +—————-+——————————— ———————–+———————–+— —————+ | | Classe d’entités topographiques qui délimite | WMS | « Canada ouvert »_ | | | empreintes de bâtiment polygonales automatiquement | | | | | extrait de données Lidar aéroportées, haute résolution | | | | | l’imagerie optique ou d’autres sources. | | | +—————-+——————————— ———————–+———————–+— —————+
Serveur
Plateforme mondiale de données sur les risques
(https://preview.grid.unep.ch/index.php?preview=home&lang=eng)
Données et modèle
À partir de preventionweb (https://risk.preventionweb.net/capraviewer/) :
L’évaluation mondiale des risques d’inondation de l’Atlas GAR utilise une approche probabiliste pour modéliser les inondations fluviales des principaux bassins fluviaux du monde entier. Cela a été possible après la compilation d’une base de données mondiale de données sur les débits, la fusion de différentes sources et la collecte de plus de 8000 stations dans le monde afin de calculer la gamme de débits possibles des échelles très faibles aux échelles maximales possibles à différents endroits le long des rivières. . Les débits calculés ont été introduits dans les tronçons de rivière pour modéliser les niveaux d’eau en aval. Cette procédure a permis de déterminer des séries d’événements stochastiques d’inondations fluviales à partir desquelles des cartes d’aléas pour plusieurs périodes de retour (25, 50, 100, 200, 500, 1000 ans) ont été obtenues. Les cartes d’aléas sont développées à une résolution de 1 km x 1 km et ont été validées par rapport aux empreintes de crues satellitaires provenant de différentes sources (archives du MPO, portail UNOSAT sur les inondations) et fonctionnent bien, en particulier pour les grands événements. surestimer par rapport à des cartes similaires produites localement (les cartes des aléas étaient disponibles pour certains pays et ont été utilisées comme référence). Le principal problème étant qu’en raison de la résolution, les cartes des risques d’inondation de l’Atlas GAR ne prennent pas en compte les défenses contre les inondations qui sont normalement présentes pour préserver la valeur exposée aux inondations.* les cartes des risques d’inondation de l’Atlas GAR ont tendance à surestimer par rapport aux cartes similaires produites localement (les cartes des risques étaient disponibles pour certains pays et ont été utilisées comme référence). Le principal problème étant qu’en raison de la résolution, les cartes des risques d’inondation de l’Atlas GAR ne prennent pas en compte les défenses contre les inondations qui sont normalement présentes pour préserver la valeur exposée aux inondations.* les cartes des risques d’inondation de l’Atlas GAR ont tendance à surestimer par rapport aux cartes similaires produites localement (les cartes des risques étaient disponibles pour certains pays et ont été utilisées comme référence). Le principal problème étant qu’en raison de la résolution, les cartes des risques d’inondation de l’Atlas GAR ne prennent pas en compte les défenses contre les inondations qui sont normalement présentes pour préserver la valeur exposée aux inondations.*
Un résumé supplémentaire est fourni dans :
UNISDR. 2015. « Rapport d’évaluation mondial sur la réduction des risques de catastrophe 2015 - Annexe
1 - Évaluation globale des risques. Genève : Nations Unies. https://www.preventionweb.net/english/hyogo/gar/2015/en/gar-pdf/Annex1-GAR_Global_Risk_Assessment_Data_methodology_and_usage.pdf.
Des détails supplémentaires sont fournis dans :
Rudari, Roberto et Francesco Silvestro. 2015. « AMÉLIORATION DU MODÈLE GLOBAL INONDATION POUR LA GAR 2015. » UNISDR.
Annexe B : Manuel d’utilisation de SOFDA
https://github.com/IBIGroupCanWest/CanFlood/tree/master/manual/sofda/